category
如何使用Hugging Face LLM(开源LLM)与您的文档、PDF以及网页中的文章进行对话。
最后,这是第一步。我已经到处找了好几个月了。
所有的文章、教程和youtube视频都只教你如何使用OpenAI做事。但老实说,这相当令人沮丧。首先,所有人工智能模型的基础都来自学术界:其次,我不敢相信,当有一个大社区在幕后工作时,我们被迫去做事情。
在这里,我将展示如何在不使用OpenAI的情况下使用免费的Google Colab笔记本与任何文档交互(我将在这里介绍文本文件、pdf文件和网站url)。由于计算的限制,我们将使用Hugging Face API和完全开源的LLM来利用LangChain库与我们的文档交互。
作为指南的简介
我对文本生成背后的技术很感兴趣,作为一名工程师,我想进行实验。但作为一个人和一名教师,我认为了解人工智能的工具和思考工具更重要。
我强烈建议你阅读詹姆斯·普朗基特的精彩文章《论生成人工智能与不自由》。引用他的话:
技术真的是我们经常想象中的中立工具吗?即技术是我们发明然后决定如何使用的东西吗?
剧透提醒:答案是否定的。
- Freedom in the age of autonomous machines
- We need to slow the hell down and do some philosophy
- medium.com
因此,我相信,我们努力理解和知道人工智能的黑匣子里发生了什么,是能够提出正确问题并开启辩论的第一步。这是一场无法避免的伦理和哲学影响的讨论,必须用社会学、政治学和经济学的概念来拒绝。
现在让我们来看看我们的python代码
附言:这篇文章的代码在我的github repo上,你可以从这里获取。
该项目
我们将使用谷歌Colab笔记本在我们的文件集上提问。您需要什么:
- 在拥抱脸网站注册(https://huggingface.co/)
- 创建一个Hugging Face Access Token(类似OpenAI API,但免费)
去拥抱脸并注册到网站
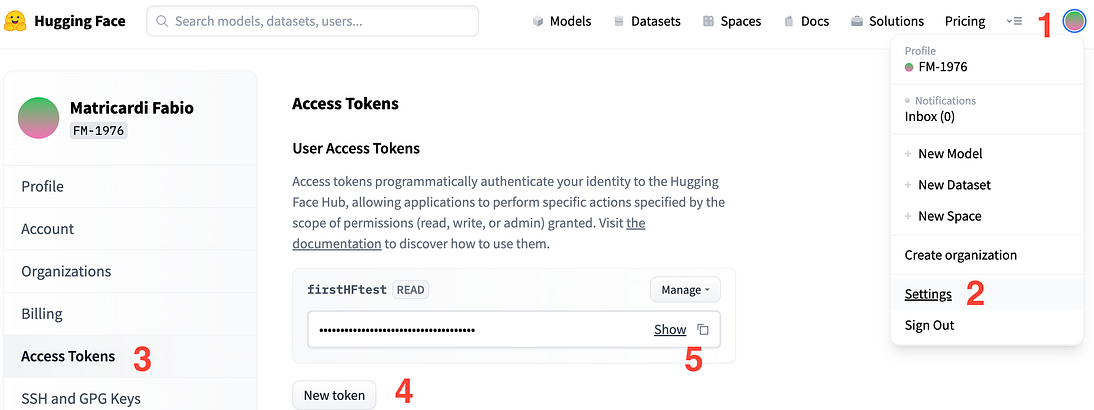
- 转到您的个人资料图标(右上角)
- 选择设置
- 在左侧面板上选择访问令牌
- 点击新代币
- 显示或复制以将其保存在秘密位置…(以及在本教程中使用它)
谷歌Colab笔记本
谷歌可乐棒极了。即使在免费层中,您也可以访问具有12 Gb RAM的运行时,并且您还有1(随机)GPU运行时,但您无法选择哪种GPU…
或者本教程不需要GPU,只需要CPU。在下一篇文章中,我将尝试使用本地LLM,因此在这种情况下,我们将需要它。
打开一个新的笔记本,让我们从安装所需的所有软件包和库开始。我们的想法是,我们将LangChain绑定到HuggingFace嵌入,将具有相似性搜索的管道与我们的文档一起输入到一个全新创建的矢量化数据库中,将其与HuggingFace访问令牌一起提供给LLM,并获得答案。
!pip install langchain !pip install huggingface_hub !pip install sentence_transformers !pip install faiss-cpu !pip install unstructured !pip install chromadb !pip install Cython !pip install tiktoken !pip install unstructured[local-inference]
LangChain、Huggingface_hub和sentence_transformers是与我们的数据和LLM模型交互的核心。FAISS Cpu是一个用于密集向量的高效相似性搜索和聚类的库。它包含的算法可以搜索任何大小的向量集,最多可以搜索可能不适合RAM的向量集。它还包含用于评估和参数调整的支持代码。Faiss是用C++编写的,带有完整的Python/numpy包装器。它由Facebook人工智能研究公司开发。
非结构化和chromadb与数据库矢量化严格相关,我们将在pdf部分专门使用它。
安装可能需要一些时间(在我的colab上大约需要2分钟…)
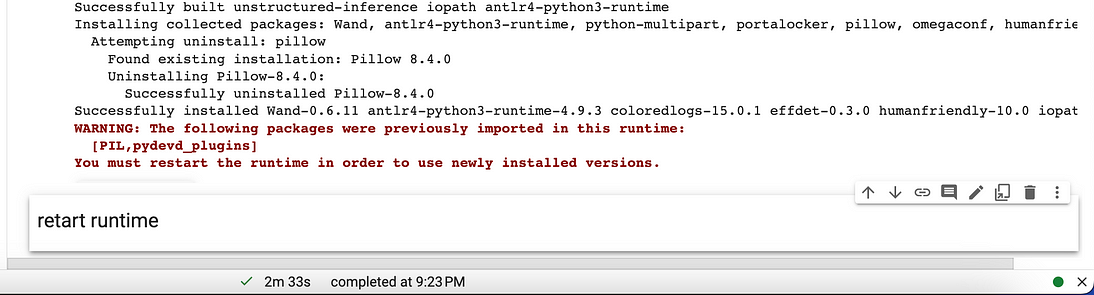
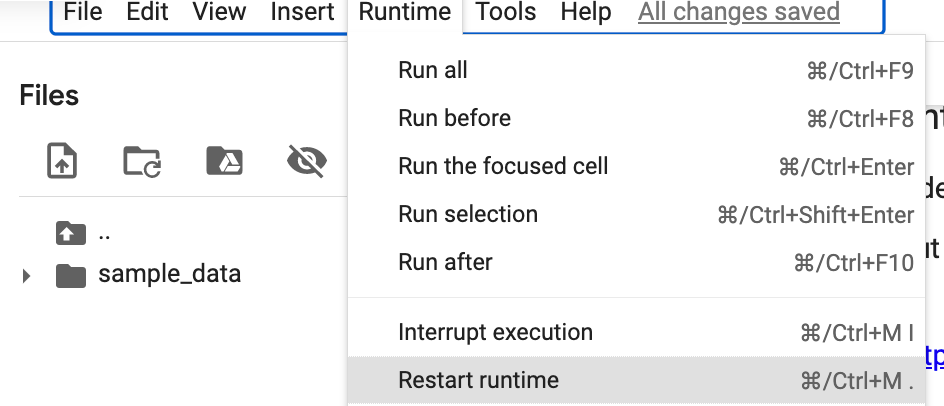
安装完成后重新启动运行时间(无论如何,Colab会告诉你…)
让我们导入库并设置我们的拥抱脸访问令牌
import os import requests os.environ["HUGGINGFACEHUB_API_TOKEN"] = "XXXXXXXXXXXXXXX"
将XXXXXXX替换为您的访问令牌(应以hf_..开头)
from langchain.document_loaders import TextLoader #for textfiles from langchain.text_splitter import CharacterTextSplitter #text splitter from langchain.embeddings import HuggingFaceEmbeddings #for using HugginFace models # Vectorstore: https://python.langchain.com/en/latest/modules/indexes/vectorstores.html from langchain.vectorstores import FAISS #facebook vectorizationfrom langchain.chains.question_answering import load_qa_chain from langchain.chains.question_answering import load_qa_chain from langchain import HuggingFaceHub from langchain.document_loaders import UnstructuredPDFLoader #load pdf from langchain.indexes import VectorstoreIndexCreator #vectorize db index with chromadb from langchain.chains import RetrievalQA from langchain.document_loaders import UnstructuredURLLoader #load urls into docoument-loader
你可以看到我在导入指令旁边评论了它的用途…
与TXT文件对话
对于这一部分,我使用了产品层次结构4.0的文本,直接形成了视频。我们从我的github repo下载它,然后使用LangChain库加载它。
import requests
url2 = "https://github.com/fabiomatricardi/cdQnA/raw/main/KS-all-info_rev1.txt"
res = requests.get(url2)
with open("KS-all-info_rev1.txt", "w") as f:
f.write(res.text)在右侧面板上,如果刷新目录结构,则可以找到新文件
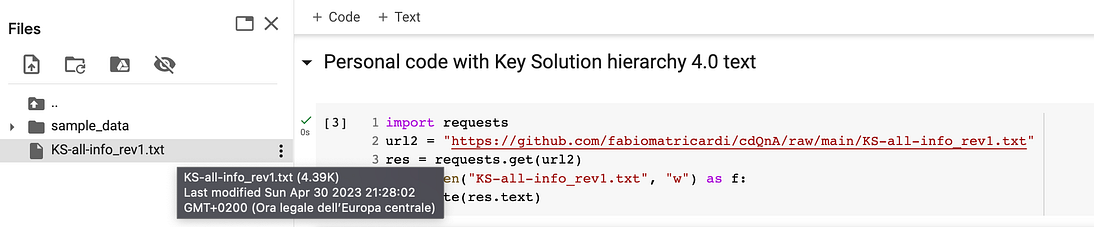
既然该文件是我们的笔记本主目录,让我们加载它,并准备一个函数来将文本打包成块(无论如何,langchain也有一个方法…)
# Document Loader
from langchain.document_loaders import TextLoader
loader = TextLoader('./KS-all-info_rev1.txt')
documents = loader.load()
import textwrap
def wrap_text_preserve_newlines(text, width=110):
# Split the input text into lines based on newline characters
lines = text.split('\n')
# Wrap each line individually
wrapped_lines = [textwrap.fill(line, width=width) for line in lines]
# Join the wrapped lines back together using newline characters
wrapped_text = '\n'.join(wrapped_lines)
return wrapped_text如果我们在空白行上运行简单的文档,则txt文件将打印在执行单元格的输出上。

将文档分割成块
LLM不能接受长指令。如果你曾经与ChatGPT或其他公司合作过,你可能已经意识到了这一点……有一个令牌限制。
现在我们有了我们的文档,接下来我们想把它分成更小的块,这样我们就可以把它放入我们的大型语言模型或嵌入中。每个模型都有一个特定的令牌大小,因此在这种情况下,我们选择的令牌大小为1000,并且您希望确保它不会超过将要使用的模型的令牌限制
出于同样的原因,我们将把文本分成块,我们还可以设置一些重叠参数(因为我们在不看单词一分为二的情况下计算到1000,所以我们可以向后设置一些字符来解决这个问题)。在我们的例子中,我们将块设置为1000,并将重叠设置为10。
# Text Splitter from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=10) docs = text_splitter.split_documents(documents)
结果存储在变量文档中,即列表中。如果我们运行len(docs),我们将得到列表的长度。
注意:在文本拆分过程中,您可能会收到一条警告……不要惊慌,您可以忘记它。
现在我们需要…嵌入
嵌入是一段信息的数字表示,例如文本、文档、图像、音频等。该表示捕获了嵌入内容的语义,使其对许多行业应用具有鲁棒性。
给定文本“What is the meaning of elephant?”,句子的嵌入可以在向量空间中表示,例如,用220个数字的列表(例如,[0.84,0.42,…,0.02])。由于这个列表捕捉了含义,我们可以做一些令人兴奋的事情,比如计算不同嵌入之间的距离,以确定两个句子的含义匹配程度。
嵌入不限于文本!您还可以创建图像的嵌入(例如,220个数字的列表),并将其与文本嵌入进行比较,以确定句子是否描述了图像。这个概念是在强大的图像搜索、分类、描述等系统下实现的!
嵌入是如何生成的?开源库叫做句子转换器,这正是我们要使用的。
# Embeddings from langchain.embeddings import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings()
一旦你运行代码,你就会发现下载的文件很少(大约500 Mb…)。这是为HuggingFace模型创建嵌入所需的二进制文件。
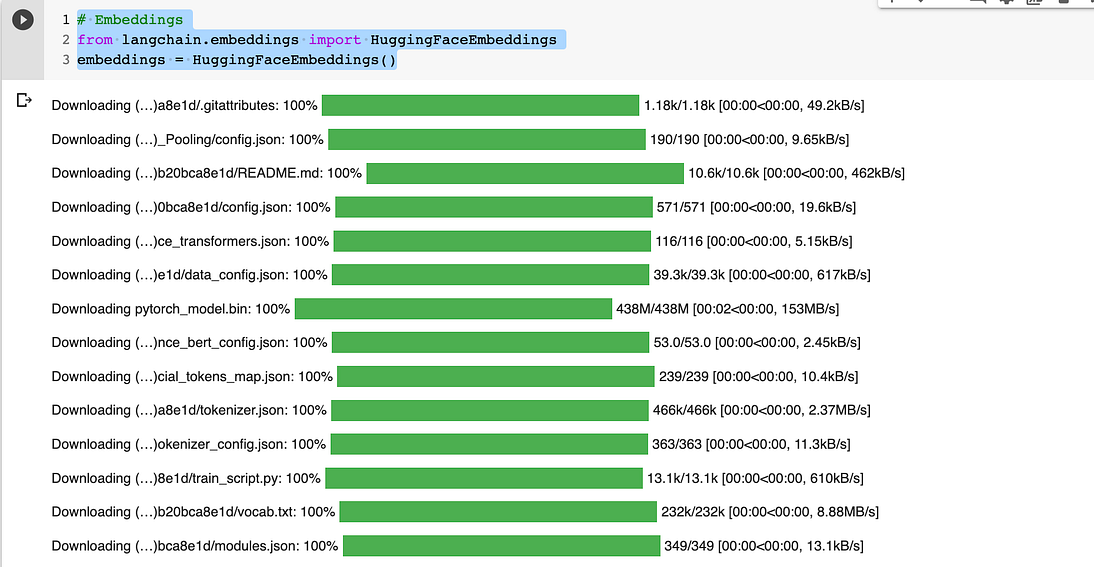
现在我们需要一个向量存储来进行嵌入。我们需要在向量存储中提供分块文档以进行信息检索,然后我们将它们与该数据库上的相似性搜索一起嵌入,作为LLM查询的上下文。
这里我们使用的是FAISS cpu,我们已经在安装阶段讨论过了。
#Create the vectorized db # Vectorstore: https://python.langchain.com/en/latest/modules/indexes/vectorstores.html from langchain.vectorstores import FAISS db = FAISS.from_documents(docs, embeddings)
我们现在可以直接在数据库上应用相似性搜索,并且在不使用任何LLM的情况下,我们将仅根据语义相似性在搜索中获得最佳命中率。默认情况下,我们有4个不同的文档相似性,但我们可以指定更多(或更少)。
注意:您可以使用此方法来获得包含特定主题的文档的引用…
query = "What is Hierarchy 4.0?" docs = db.similarity_search(query)
如果你运行下面的两个单元格,你可以看到搜索结果和文档列表的维度。
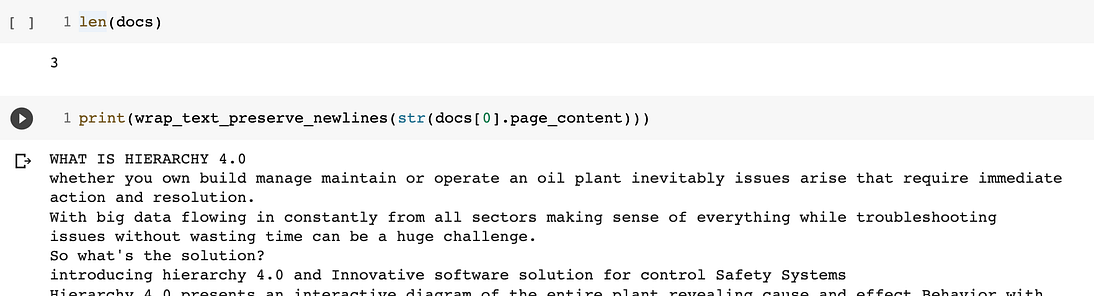
最后,让我们来谈谈Hugging Face LLM的文档
到目前为止,我们所做的是为接下来的事情做准备:从拥抱脸中询问一个大型语言模型,与我们互动,将我们的知识库和问题整合在一起。
作业所需的2个调用和2条指示非常直接:
from langchain.chains.question_answering import load_qa_chain from langchain import HuggingFaceHub
然后,我们定义了要与我们的访问令牌一起使用的LLM,并告诉python启动我们的相似性搜索请求,该搜索嵌入了我们对所选LLM的问题
llm=HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":512})
chain = load_qa_chain(llm, chain_type="stuff")为了这个测试的目的,我向您展示flan-t5-xl。首先,因为这是我受到启发的例子;然后是因为在开源LLM中,flan-t5被奇怪地低估了,但确实很强大。Prompt Engineering频道的一段youtube视频启发了我:他是先驱,我只是跟踪并试验了一下。
好的,现在我们创建了一个名为“stuff”的问答链,将发送到我们的llm(如上所述)。我们如何提问?这很容易!我们给出或输入我们的问题,在矢量化数据库上创建相似性搜索,然后我们运行链,将所有这些放在一起,
query = "What the actual issues and drawbacks ?" docs = db.similarity_search(query) chain.run(input_documents=docs, question=query)
如果你想要一个互动式的问题,把第一行改成这样:
query = input("What is your question: ")结果比较好
The actual method is time consuming due to the involvement of several specialists and other maintenance activities have been delayed as a result. The new method is more efficient and can be used to solve the issue in few simple steps.
注意:第一次运行可能有点慢。如果花费的时间超过5分钟,则意味着从API到Hugging Face将出现错误。停止运行该单元格,尝试运行另一个单元格,然后再次运行。
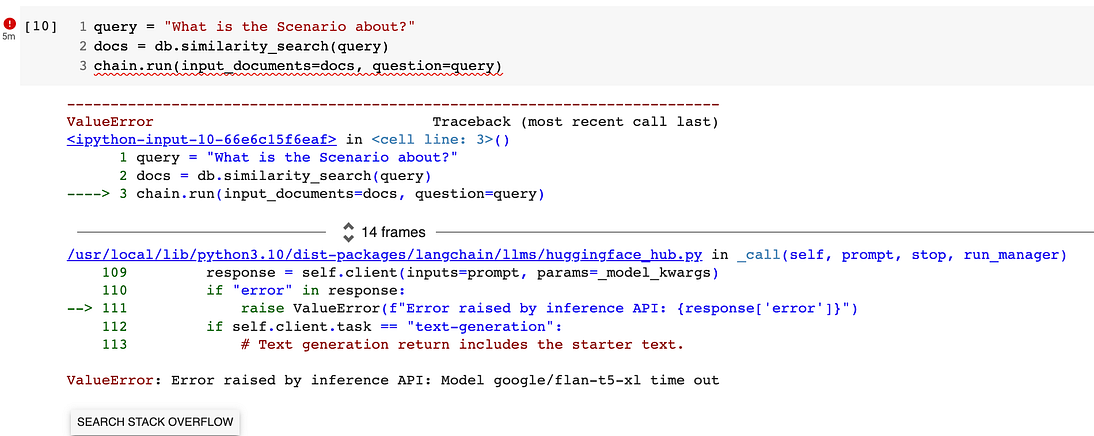
你可以尝试更多的问题并评估答案。我相信这已经是一个好结果了。
其他LLM呢?
那我们为什么不试试其他型号呢?顺便说一句,这就是我最初的动机。所以我首先想到的是使用维库纳模型(他们说它的质量超过了著名的GPT-4的90%)。
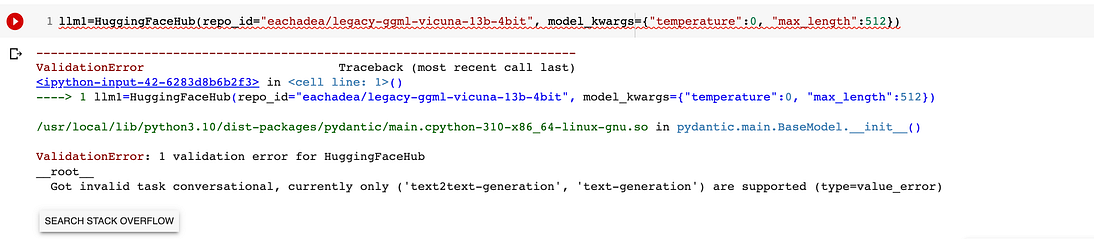
所以我上了《拥抱的脸》,拍了一个很好的维库纳模型(eachadea/legacy-ggml-Vicuna-13b-4bit)并尝试了一下。这很容易:
llm1=HuggingFaceHub(repo_id="eachadea/legacy-ggml-vicuna-13b-4bit", model_kwargs={"temperature":0, "max_length":512})
chain = load_qa_chain(llm1, chain_type="stuff")
#our questions
query = "What is the case study challenge"
docs = db.similarity_search(query)
chain.run(input_documents=docs, question=query)在这里,我的希望破灭了。我遇到了一个意想不到的错误:所以我试图理解它,我得到的是,你只能用text2文本生成或文本生成模型来进行搜索(管道只做特定的事情…)。
所以我开始浏览HuggingFace的text2文本生成模型。正如你所看到的,他们真的有很多(12k)。
你会在github笔记本上看到我所有的测试:我尝试了很多,令人惊讶的是,我发现一些相对较小的参数模型真的很有效(MBZUAI/LaMini-Flan-T5–783M就是其中之一…)
还有一点需要注意的是:如果你选择的模型太大,那么API很可能不会被接受,并且会超时。
提示和技巧:始终验证您正在测试的模型是否激活/启用了推断API。看图片(第一张还好,第二张不好…)

在我的测试中,我看到了很多不好的答案,但也有一些部分非常好。做你自己的尝试,为你选择更好的。
llm6=HuggingFaceHub(repo_id="MBZUAI/LaMini-Flan-T5-783M", model_kwargs={"temperature":0, "max_length":512})
chain = load_qa_chain(llm6, chain_type="stuff")这里的结果还不错——一部分重复了几次
query = "What the actual issues and drawbacks ?" docs = db.similarity_search(query) chain.run(input_documents=docs, question=query)
The actual issues and drawbacks of using the actual method are: 1) possibility of human error 2) incorrect impact analysis report 3) time consuming troubleshooting process 4) delayed maintenance activities 5) lack of a comprehensive overview of all signals allocated in the specified controller 6) lack of a user-friendly interface 7) lack of a comprehensive database of all the data 8) lack of a user-friendly interface 9) lack of a user-friendly interface 10) lack of a user-friendly interface
最后,我选了declare-lab/flan-alpaca-large。它工作得很好,没有幻觉。
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub
llm2=HuggingFaceHub(repo_id="declare-lab/flan-alpaca-large", model_kwargs={"temperature":0, "max_length":512})
chain = load_qa_chain(llm2, chain_type="stuff")
query = "What the actual issues and drawbacks ?"
docs = db.similarity_search(query)
chain.run(input_documents=docs, question=query)结果相当不错!😁
The actual method is time consuming due to the involvement of several
specialists and other maintenance activities have been delayed as a result.
The new method is more efficient and can be used to solve the issue in
few simple steps.
如何加载其他类型的文档?
LangChain是一个非常棒的图书馆。它可以帮助您开箱即用地连接到各种各样的文档(谷歌文档、电子表格、黑名单笔记…)
这里有完整的文档…
在参考的GitHub笔记本中,我放了一个pdf部分和一个url部分。机制相同,只是更改了加载程序(不再是文本加载程序,而是pdf加载程序[UnstructuredPDFLoader]和url加载程序[UunstructuredURLLoader)。
与pdf对话
对于pdf部分,我从github中获取了Medium中我的两篇文章的打印pdf:然后我将它们复制到一个特定的文件夹中,并要求UnstructuredPDFLoader加载所有这些文章。
!wget https://github.com/fabiomatricardi/cdQnA/raw/main/PLC_mediumArticle.pdf
!wget https://github.com/fabiomatricardi/cdQnA/raw/main/BridgingTheGaap_fromMedium.pdf
!mkdir pdfs
!cp *pdf '/content/pdfs'
# connect your Google Drive
#from google.colab import drive
#drive.mount('/content/gdrive', force_remount=True)
import os
pdf_folder_path = '/content/pdfs'
os.listdir(pdf_folder_path)
loaders = [UnstructuredPDFLoader(os.path.join(pdf_folder_path, fn)) for fn in os.listdir(pdf_folder_path)]
loaders之后,我们使用chromadb作为嵌入的矢量索引数据库(不要忘记使用令牌块的文本拆分器)
index = VectorstoreIndexCreator(
embedding=HuggingFaceEmbeddings(),
text_splitter=CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)).from_loaders(loaders)
#Load llm with selected one
llm2=HuggingFaceHub(repo_id="declare-lab/flan-alpaca-large", model_kwargs={"temperature":0, "max_length":512})
#Prepare the pipeline
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm2,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
#get reply to our questions
chain.run('What is the difference between a PLC and a PC?')我觉得结果不错
PLCs are built to operate in industrial settings with varying temperatures,
vibrations, and humidity levels, and are highly resistant to electrical noise.
与网站对话
对于网页部分,我选择了2个与PLC编程相关的网站,并将URL添加到列表中
urls = [ "https://basicplc.com/plc-programming/", "https://www.learnrobotics.org/blog/plc-programming-languages/" ]
根据同样的原则,这次我们使用UnstructuredURLLoader来加载我们的网站内容并对其进行矢量化。
from langchain.document_loaders import UnstructuredURLLoader
urls = [
"https://basicplc.com/plc-programming/",
"https://www.learnrobotics.org/blog/plc-programming-languages/"
]
loader2 = [UnstructuredURLLoader(urls=urls)]Chromadb会向您发出警告,但我们知道我们正在使用一个临时数据库…
index2 = VectorstoreIndexCreator(
embedding=HuggingFaceEmbeddings(),
text_splitter=CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)).from_loaders(loader2)现在是时候把我们选择的llm与嵌入的向量索引和我们的问题放在一起了。
llm2=HuggingFaceHub(repo_id="declare-lab/flan-alpaca-large", model_kwargs={"temperature":0, "max_length":512})
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm2,
chain_type="stuff",
retriever=index2.vectorstore.as_retriever(),
input_key="question")
chain.run('What is ladder diagram?')在我看来,结果相当不错…
Ladder Logic Programming is a PLC programming language that is
used to create a diagram that shows the connections between
inputs and outputs. It is derived from the Relay Logic Diagrams
and uses almost the same context.
接下来会发生什么?
现在就这样。
本文的全部代码都在这里。
我建议你直接在Google Colab中打开它并保存一份副本。
我接下来想做的是能够在Google Colab上使用本地模型(没有任何外部API令牌),如Vicuna、Koala或Alpaca。
LangChain有能力连接到llama.cpp,问题是我不知道怎么做。
如果社区能帮助我,我会很高兴地分享它(如何启动和运行Vicuna,如何启用API服务,激活代理并使它们交互)。
为什么不创建一个用户界面呢!
无论如何,我会继续我的探索!
是否要在仅在CPU上运行的本地计算机上安装ChatGPT?
- GPT4All is the Local ChatGPT for your documents… and it is free!
- How to install GPT4All on your Laptop and ask AI about your own domain knowledge (your documents)… and it runs on CPU…
- artificialcorner.com
如果这个故事提供了价值,并且你想表示一点支持,你可以:
为这个故事鼓掌50次(这真的,真的帮助了我)
你想学习如何使用仅在CPU上运行的新LaMini LM模型,自己总结长文本、论文或视频记录吗?读这个。
- 登录 发表评论