
Langchain LLM代理简介:当RAG不够时
人工智能助手大脑结构的一阶原理
Hello everyone, this article is a written form of a tutorial I conducted two weeks ago with Neurons Lab. If you prefer a narrative walkthrough, you can find the YouTube video here:
As always, you can find the code on GitHub, and here are separate Colab Notebooks:
【LangChain】使用LangChain(而非OpenAI)回答有关文档的问题
如何使用Hugging Face LLM(开源LLM)与您的文档、PDF以及网页中的文章进行对话。
最后,这是第一步。我已经到处找了好几个月了。
所有的文章、教程和youtube视频都只教你如何使用OpenAI做事。但老实说,这相当令人沮丧。首先,所有人工智能模型的基础都来自学术界:其次,我不敢相信,当有一个大社区在幕后工作时,我们被迫去做事情。
在这里,我将展示如何在不使用OpenAI的情况下使用免费的Google Colab笔记本与任何文档交互(我将在这里介绍文本文件、pdf文件和网站url)。由于计算的限制,我们将使用Hugging Face API和完全开源的LLM来利用LangChain库与我们的文档交互。
作为指南的简介
我对文本生成背后的技术很感兴趣,作为一名工程师,我想进行实验。但作为一个人和一名教师,我认为了解人工智能的工具和思考工具更重要。
我强烈建议你阅读詹姆斯·普朗基特的精彩文章《论生成人工智能与不自由》。引用他的话:
技术真的是我们经常想象中的中立工具吗?即技术是我们发明然后决定如何使用的东西吗?
【LangChain】与文档聊天:将OpenAI与LangChain集成的终极指南
欢迎来到人工智能的迷人世界,在那里,人与机器之间的通信越来越模糊。在这篇博客文章中,我们将探索人工智能驱动交互的一个令人兴奋的新前沿:与您的文本文档聊天!借助OpenAI模型和创新的LangChain框架的强大组合,您现在可以将静态文档转化为交互式对话。
你准备好彻底改变你使用文本文件的方式了吗?然后系好安全带,深入了解我们将OpenAI与LangChain集成的终极指南,我们将一步一步地为您介绍整个过程。
什么是LangChain?
LangChain是一个强大的框架,旨在简化大型语言模型(LLM)应用程序的开发。通过为各种LLM、提示管理、链接、数据增强生成、代理编排、内存和评估提供单一通用接口,LangChain使开发人员能够将LLM与真实世界的数据和工作流无缝集成。该框架允许LLM通过合并外部数据源和编排与不同组件的交互序列,更有效地解决现实世界中的问题。
我们将在下面的示例应用程序中使用该框架从文本文档源生成嵌入,并将这些内容持久化到Chroma矢量数据库中。然后,我们将使用LangChain在后台使用OpenAI语言模型来查询用户提供的问题,以处理请求。
这将使我们能够与自己的文本文档聊天。
【privateGPT】使用privateGPT训练您自己的LLM
了解如何在不向提供商公开您的私人数据的情况下训练您自己的语言模型
使用OpenAI的ChatGPT等公共人工智能服务的主要担忧之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用人工智能技术的公司最大的担忧。
很多时候,你想创建自己的语言模型,根据你的数据集(如销售见解、客户反馈等)进行训练,但同时你不想将所有这些敏感数据暴露给OpenAI等人工智能提供商。因此,理想的方法是在本地训练自己的LLM,而无需将数据上传到云。
如果你的数据是公开的,并且你不介意将它们暴露给ChatGPT,我有另一篇文章展示了如何将ChatGPT与你自己的数据连接起来:
【LLM】LangChain 的Callbacks 改进
TL;DR:我们宣布对我们的回调系统进行改进,该系统支持日志记录、跟踪、流输出和一些很棒的第三方集成。这将更好地支持具有独立回调的并发运行,跟踪深度嵌套的LangChain组件树,以及范围为单个请求的回调处理程序(这对于在服务器上部署LangChain非常有用)。
【LLM】LangChain整合Gradio和LLM代理
编者按:这是Gradio的软件工程师Freddy Boulton的一篇客座博客文章。我们很高兴能分享这篇文章,因为它为生态系统带来了大量令人兴奋的新工具。代理在很大程度上是由他们所拥有的工具定义的,所以能够为他们配备所有这些gradio_tools对我们来说是非常令人兴奋的!
重要链接:
大型语言模型(LLM)给人留下了深刻的印象,但如果我们能赋予它们完成专门任务的技能,它们可以变得更加强大。
【LLM】LangChain 利用上下文压缩改进文档检索
注意:这篇文章假设你对LangChain有一定的熟悉程度,并且是适度的技术性文章。
💡 TL;DR:我们引入了新的抽象和新的文档检索器,以便于对检索到的文档进行后处理。具体来说,新的抽象使得获取一组检索到的文档并仅从中提取与给定查询相关的信息变得容易。
介绍
许多LLM支持的应用程序需要一些可查询的文档存储,以便检索尚未烘焙到LLM中的特定于应用程序的信息。
假设你想创建一个聊天机器人,可以回答有关你个人笔记的问题。一种简单的方法是将笔记嵌入大小相等的块中,并将嵌入的内容存储在向量存储中。当你问系统一个问题时,它会嵌入你的问题,在向量存储中执行相似性搜索,检索最相关的文档(文本块),并将它们附加到LLM提示中。
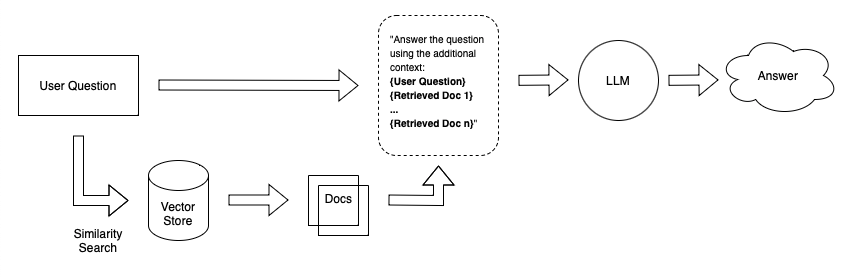
A simple retrieval Q&A system
【LLM】LangChain自定义智能体
我们听到的最常见的要求之一是为创建自定义智能体提供更好的功能和文档。这一直有点棘手,因为在我们看来,实际上还不清楚“智能体”到底是什么,因此它们的“正确”抽象可能是什么。最近,我们感觉到一些抽象开始融合在一起,所以我们在Python和TypeScript模块上做了一个大的努力,以更好地执行和记录这些抽象。请参阅下面的技术文档链接,然后是我们介绍的抽象和未来方向的描述。
【LLM】LLMs 和 SQL
Francisco Ingham和Jon Luo是领导SQL集成变革的两名社区成员。我们真的很高兴能写这篇博客文章,让他们复习他们学到的所有技巧和窍门。我们更高兴地宣布,我们将与他们进行一个小时的网络研讨会,讨论这些知识并提出其他相关问题。本次网络研讨会将于3月22日举行-请在以下链接注册:
LangChain库有多个SQL链,甚至还有一个SQL代理,旨在使与存储在SQL中的数据的交互尽可能简单。以下是一些相关链接:
【LangChain】LangChain和原生矢量存储Chroma
今天,我们宣布LangChain与Chroma的集成,这是迈向现代A.I Stack的第一步。
LangChain-人工智能原生开发者工具包
我们启动LangChain的目的是建立一个模块化和灵活的框架,用于开发a.I原生应用程序。一些立即浮现在脑海中的用例是聊天机器人、问答服务和代理。成千上万的开发人员现在正在使用LangChain灵活、易于使用的框架进行黑客攻击、修补和构建各种LLM驱动的应用程序。
应用程序的关键组件之一是嵌入,以及保存和使用这些嵌入的向量存储。
我们注意到许多现有向量存储的一个痛点是,它们通常涉及连接到存储嵌入的外部服务器。虽然这对于将应用程序投入生产来说很好,但在本地轻松地原型化应用程序确实有点棘手。
我们为本地矢量存储提供的最佳解决方案是使用FAISS,许多社区成员指出,FAISS存在一些棘手的依赖关系,导致安装问题。
Chroma-人工智能原生矢量存储
Chroma的成立是为了构建利用嵌入功能的工具。嵌入是表示任何类型数据的人工智能原生方式,使其非常适合使用各种人工智能工具和算法。