category
欢迎来到人工智能的迷人世界,在那里,人与机器之间的通信越来越模糊。在这篇博客文章中,我们将探索人工智能驱动交互的一个令人兴奋的新前沿:与您的文本文档聊天!借助OpenAI模型和创新的LangChain框架的强大组合,您现在可以将静态文档转化为交互式对话。
你准备好彻底改变你使用文本文件的方式了吗?然后系好安全带,深入了解我们将OpenAI与LangChain集成的终极指南,我们将一步一步地为您介绍整个过程。
什么是LangChain?
LangChain是一个强大的框架,旨在简化大型语言模型(LLM)应用程序的开发。通过为各种LLM、提示管理、链接、数据增强生成、代理编排、内存和评估提供单一通用接口,LangChain使开发人员能够将LLM与真实世界的数据和工作流无缝集成。该框架允许LLM通过合并外部数据源和编排与不同组件的交互序列,更有效地解决现实世界中的问题。
我们将在下面的示例应用程序中使用该框架从文本文档源生成嵌入,并将这些内容持久化到Chroma矢量数据库中。然后,我们将使用LangChain在后台使用OpenAI语言模型来查询用户提供的问题,以处理请求。
这将使我们能够与自己的文本文档聊天。
设置项目
创建一个新的项目文件夹并安装以下Python包:
pip install langchain openai chromadb tiktoken
命令pip-install langchain openai chromadb tiktoken用于使用Python包管理器pip安装四个Python包。每个包都有特定的用途,它们共同帮助您将LangChain与OpenAI模型集成,并管理应用程序中的令牌。让我们对所涉及的程序包进行细分:
- langchain:这个包是主要的langchain库,它有助于与OpenAI模型无缝集成,以创建与文本文档的交互式聊天体验。
- openai:这是openai API的官方Python包,使您能够使用openai提供的强大语言模型,例如GPT-4。
- chromadb:ChrmaDB是一个轻量级、高性能、无模式的矢量数据库,专为人工智能应用程序设计。它允许您存储、检索和管理LangChain和OpenAI支持的文档聊天应用程序所需的矢量数据(嵌入)。
- tiktoken:tiktoken是OpenAI提供的一个实用程序库,它可以帮助您计算和管理文本字符串中的标记,而无需进行API调用。这对于监控令牌使用情况、保持在API限制内以及有效地使用OpenAI的模型都很有用。
通过执行此命令,您可以安装所有必要的软件包,以开始构建和部署使用OpenAI的LangChain的文本文档聊天应用程序。
将以下两个文件添加到项目文件夹中:
touch init_vectorstore.py ask.py
此外,我们还将一个txt文档添加到项目中。对于本文的示例,国情咨文文本添加为State_of_the_Union.txt,如您所见:
让我们开始将以下Python代码添加到文件init_vectorstore.py中。
该代码读取文本文档,将其拆分为更小的块,并使用OpenAI模型生成嵌入。然后,它创建并持久化一个包含嵌入和相关元数据的Chroma数据库。这允许有效地存储和检索文档嵌入,用于人工智能驱动的文本分析和交互。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import os
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPEN AI API KEY HERE]"
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": f"Text chunk {i} of {len(texts)}"} for i in range(len(texts))], persist_directory="db")
docsearch.persist()
docsearch = None以下是对代码的逐步描述:
- 导入必要的库和模块:
- langchain.embeddings.openai中的openai嵌入,以使用openai模型并生成嵌入。
- 来自langchain.text_splitter的CharacterTextSplitter,用于将输入文本拆分为更小的块。
- langchain.vectorstores中的Chroma,用于创建Chroma数据库以存储嵌入和元数据。
- 用于处理环境变量的操作系统。
- 使用os.environ将OpenAI API密钥设置为环境变量。要获取您的OpenAI API密钥,请在OpenAI的官方网站注册帐户(https://www.openai.com/)。一旦您的帐户获得批准,请导航到帐户设置或仪表板下的API密钥部分。你会在那里找到你唯一的API密钥,你可以用它来访问OpenAI的模型和服务。
- 打开“state_of_the_union.txt”文件的内容并将其读取到一个名为state_of_the_union的变量中。
- 创建一个CharacterTextSplitter实例,其chunk_size为1000个字符,chunk_overlap为0,这意味着块之间没有重叠的字符。
- 使用text_splitter实例的Split_text方法将state_of_the_union文本拆分为块。
- 创建一个名为embeddings的OpenAIEmbeddings实例,以使用OpenAI模型生成文档嵌入。
- 使用from_texts()方法实例化Chroma对象,该方法采用以下参数:
- texts:前面生成的文本块。
- embeddings:用于生成嵌入的OpenAIEmbeddings实例。
- 元数据:每个文本块的元数据字典列表。
- persist_directory:存储Chroma数据库的目录(在本例中为“db”)。
- 8.使用Persist()方法将Chroma对象持久化到指定的目录。
- 9.将docsearch变量设置为None以将其从内存中清除。
总之,此代码读取文本文档,将其拆分为更小的块,使用OpenAI模型生成嵌入,使用生成的嵌入和元数据创建Chroma数据库,并将数据库保存到指定的目录中以备将来使用。
让我们运行以下代码,通过使用以下命令为Chroma矢量数据库创建嵌入内容:
python init_vectorstore.py
然后,您应该会收到以下输出:
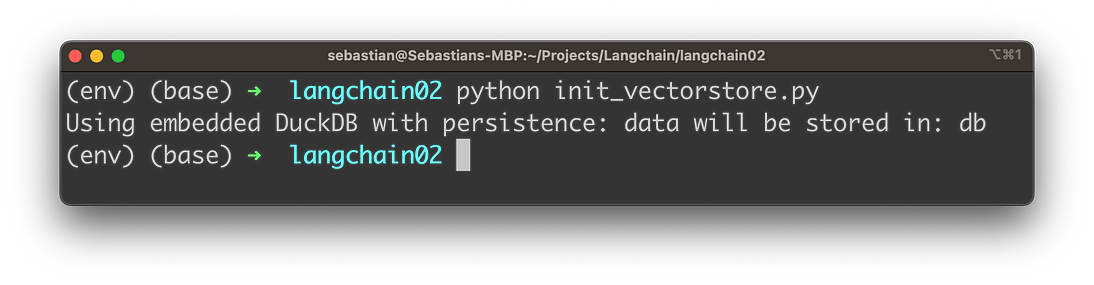
在您的项目文件夹中,您应该能够找到一个包含一些内容的数据库子文件夹。

与文本文档交互
让我们用文件ask.py中的文本文档实现交互逻辑。下面的代码演示了如何使用LangChain、OpenAI模型和包含嵌入的Chroma数据库创建问答(QA)系统。Chroma矢量数据库已经在最后一步中与我们的内容一起准备好了,因此我们现在准备好利用它:
from langchain.chains import RetrievalQAWithSourcesChain
from langchain import OpenAI
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "[INSERT YOUR OPEN AI API KEY HERE]"
embeddings = OpenAIEmbeddings()
docsearch = Chroma(persist_directory="db", embedding_function=embeddings)
chain = RetrievalQAWithSourcesChain.from_chain_type(OpenAI(temperature=0), chain_type="stuff", retriever=docsearch.as_retriever())
user_input = input("What's your question: ")
result = chain({"question": user_input}, return_only_outputs=True)
print("Answer: " + result["answer"].replace('\n', ' '))
print("Source: " + result["sources"])以下是代码的说明:
- 导入必要的库和模块,包括RetrievalQAWithSourcesChain、OpenAI、Chroma和OpenAI嵌入。
- 使用os.environ将OpenAI API密钥设置为环境变量。
- 创建一个名为embeddings的OpenAIEmbeddings实例,以使用OpenAI模型生成文档嵌入。
- 使用persist_directory参数(存储先前创建的Chroma数据库的位置)和embedding_function参数(embeddings实例)实例化Chroma对象。
- 使用from_chain_type()方法创建RetrievalQAWithSourcesChain实例。此实例采用以下参数:
- OpenAI(temperature=0):具有指定温度设置的OpenAI类的实例。
- chain_type=“stuff”:要创建的链的类型(在本例中为“stuff“)。
- retriever=docsearch.as_retriever():retriever对象,它是使用as_retriever()方法转换为retriever的Chroma实例。
- 使用input()函数提示用户输入问题。
- 将用户的问题传递给QA系统(链实例)并检索结果。
- 打印答案和答案来源,并从答案文本中删除换行符。
总之,这段代码使用LangChain、OpenAI模型和Chroma数据库创建了一个简单的QA系统。它提示用户提出问题,使用QA系统处理问题,并返回答案及其来源——让我们看看它的实际操作。使用启动脚本
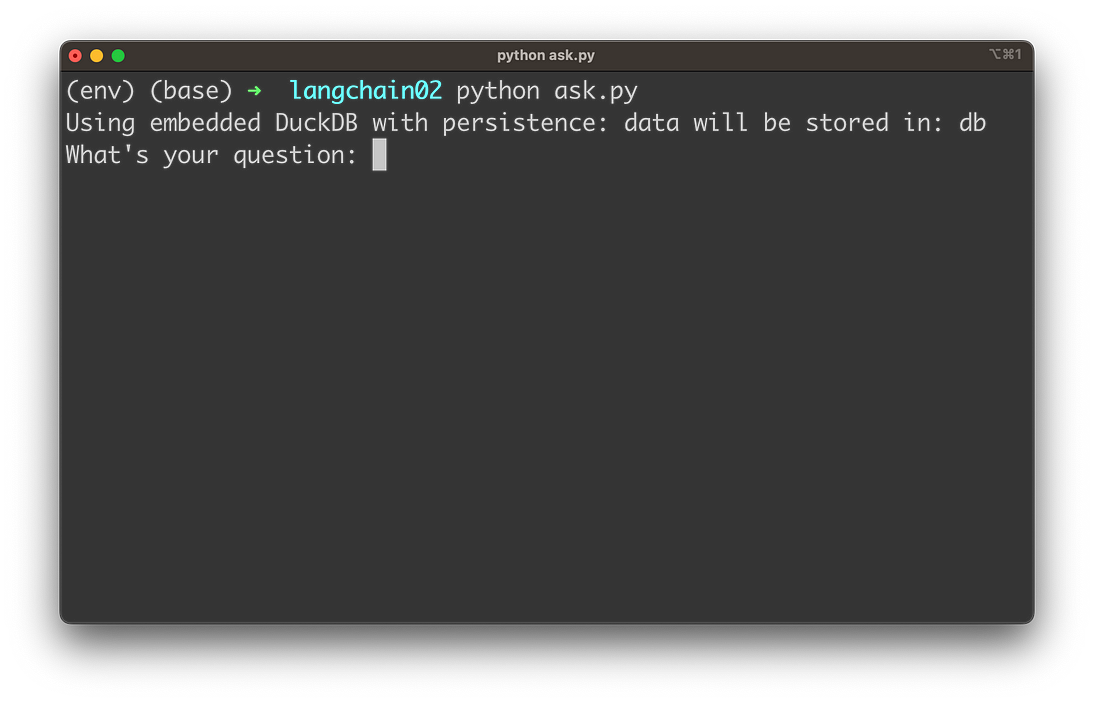
python ask.py
然后要求您输入问题:
输入与国情咨文文本的任何内容相关的问题,例如:
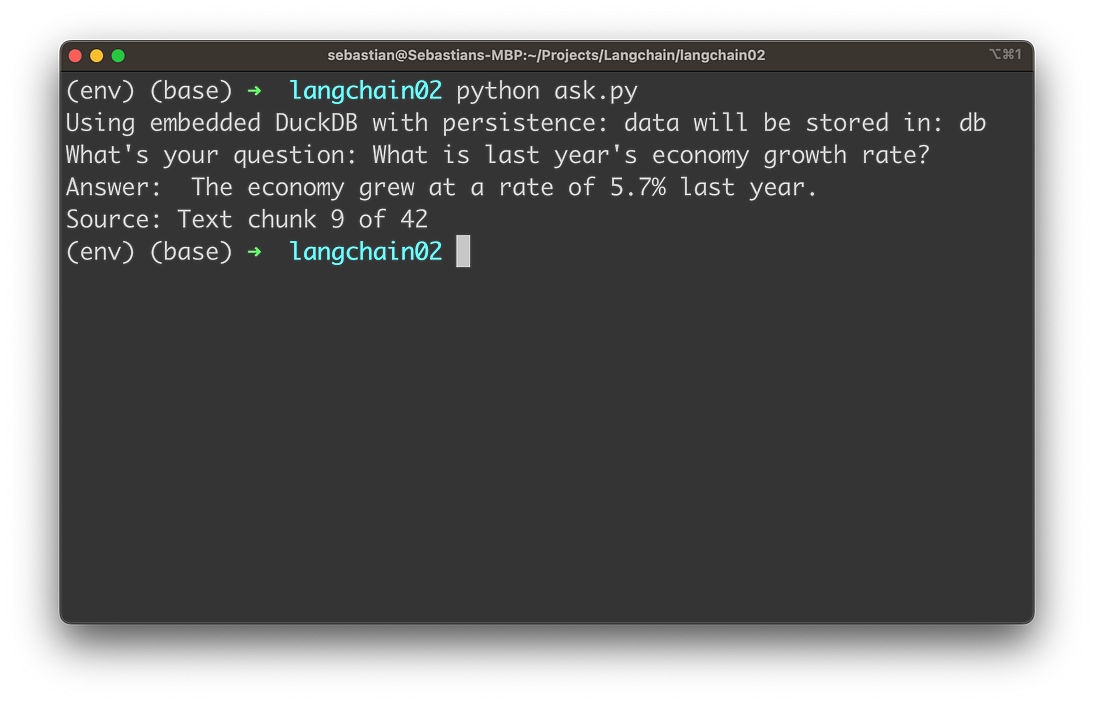
然后,您将收到答案以及用于从中检索必要信息的文本块的源信息。
这使我们现在可以通过在后台使用OpenAI的语言模型来询问与文本文档相关的任何问题。
结论
OpenAI模型和LangChain的强大结合为改变我们与文本文档的交互方式开辟了新的可能性。正如我们在本指南中所展示的,集成这些尖端技术从未如此容易。
- 登录 发表评论