
一些迁移到Mastodon的Twitter用户错过了对自己的toots进行全文搜索的机会。以下是如何使用R和 rtoot p包搜索您自己的帖子。
无论你是从Twitter完全迁移到了Mastodon,只是在试用“fediverse”,还是长期使用Mastodon的用户,你都可能会错过搜索“toots”(也称为帖子)全文的机会。在Mastodon中,标签是可搜索的,但其他非标签文本是不可搜索的。全文搜索的不可用性让用户可以控制他们的内容有多少容易被陌生人发现。但如果你想搜索自己的帖子呢?
一些Mastodon实例允许用户对自己的嘟嘟进行全文搜索,但其他实例则不允许,具体取决于管理员。幸运的是,由于R和David Schoch开发的rtot包,可以轻松全文搜索您自己的Mastodon帖子。这就是本文的主旨。
目录
- 设置全文搜索
- 提取并保存数据
- 使用您的结果创建可搜索的表
- 如何拉入新的Mastodon桩
- 如何阅读下载的Mastodon存档
设置全文搜索
首先,如果您的系统上没有安装rtot包(“rtot”),请安装它。我还将使用dplyr和DT包。可以使用以下命令加载这三个文件:
# install.packages("rtoot") # if needed
library(rtoot)
library(dplyr)
library(DT)
接下来,您需要您的Mastodon ID,它与您的用户名和实例不同。rtot包包括一种在联邦快递中搜索账户的方法。如果你想知道某人是否在Mastodon上有账户,这是一个有用的工具。但由于它还返回帐户ID,您也可以使用它来查找自己的ID。
要搜索我自己的ID,我会使用:
accounts <- search_accounts("smach@fosstodon.org")
这可能只会带回一个结果的数据帧。如果只搜索用户名而不搜索实例,例如search_accounts(“posit”),以查看posit(以前的RStudio)是否在Mastodon上处于活动状态,则可能会有更多结果。
我的搜索只有一个结果,因此我的ID是ID列中的第一个(也是唯一的)项目:
my_id <- accounts$id[1]
我现在可以使用rtot的get_account_statuses()函数检索我的帖子。
提取并保存数据
默认值返回20个结果,至少目前是这样,但如果使用limit参数手动设置,则限制值似乎要高得多。不过,请务必利用这一设置,因为大多数Mastodon实例都是由志愿者运行的,最近托管成本大大增加。
第一次尝试提取自己的数据时,将要求您进行身份验证。我运行以下命令来获取我最近的50篇文章(注意使用verbose=TRUE来查看可能返回的任何消息):
smach_statuses <- get_account_statuses(my_id, limit = 50, verbose = TRUE)
接下来,我被问到是否要进行身份验证。选择“是”后,我收到以下查询:
On which instance do you want to authenticate (e.g., "mastodon.social")?
重要的
尽管“mastodon.social”的例子包括引号,但对我有效的回应是我的例子没有引号;也就是说,只有fosstodon.org,而不是“fosstodonorg”。
接下来,我被问到:
What type of token do you want?
1: public
2: user
因为我想让权限查看我自己帐户中的所有活动,所以我选择了user。然后,包为我存储了一个身份验证令牌,然后我可以运行get_account_statuses()。
生成的数据帧实际上是一个tibble,一种由tidyverse包使用的特殊类型的数据帧,包括29列。一些是列表列,如account和media_attachments,其中包含非原子结果,这意味着结果不是严格的二维格式。
我建议在进一步操作之前保存此结果,以便在R会话或代码出错时不需要重新ping服务器。我通常使用saveRDS,如下所示:
saveRDS(smach_statuses,“smach_stateses.Rds”)
由于列表列复杂,尝试将结果保存为拼花文件不起作用。使用vroom包将其另存为CSV文件,并包含列表列的全文。但是,我宁愿保存为本机.Rds或.Rdata文件。
使用您的结果创建可搜索的表
如果您只需要一个用于全文搜索的可搜索表,那么只需要这29列中的几列。您肯定需要created_at、url、剧透_text(如果您使用内容警告并希望这些警告出现在表中)和内容。如果您错过了帖子中的敬业度指标,请添加reblogs_count、proportes_count和replies_count。
下面是我用来为可搜索表创建数据以供自己查看的代码。我添加了一个URL列,以创建一个带有帖子URL的可点击>>,然后将其添加到每个帖子内容的末尾。这样就可以很容易地点击到原始版本:
tabledata <- smach_statuses |>
filter(content != "") |>
# filter(visibility == "public") |> # If you want to make this public somewhere. Default includes direct messages.
mutate(
url = paste0("<a target = 'blank' href = '", uri,"'><strong> >></strong></a>"),
content = paste(content, url),
created_at := as.character(as.POSIXct(created_at, format = "%Y-%m-%d %H:%M UTC"))
) |>
select(CreatedAt = created_at, Post = content, Replies = replies_count, Favorites = favourites_count, Boosts = reblogs_count)
若我公开共享这个表,我会确保取消注释过滤器(visibility==“public”),以便只有我的公开帖子可用。get_account_statuses()为您自己的帐户返回的数据包括未列出的帖子(任何找到它们的人都可以看到,但默认情况下不在公共时间线上)以及仅为关注者或直接消息设置的帖子。
有很多方法可以将这些数据转换为可搜索的表。一种方法是使用DT包。下面的代码创建了一个交互式HTML表,其中包含可以使用正则表达式的搜索筛选框。(有关使用DT的更多信息,请参阅使用R:快速交互式HTML表。)
DT::datatable(tabledata, filter = 'top', escape = FALSE, rownames = FALSE,
options = list(
search = list(regex = TRUE, caseInsensitive = TRUE),
pageLength = 20,
lengthMenu = c(25, 50, 100),
autowidth = TRUE,
columnDefs = list(list(width = '80%', targets = list(2)))
))
下面是生成的表格的屏幕截图:
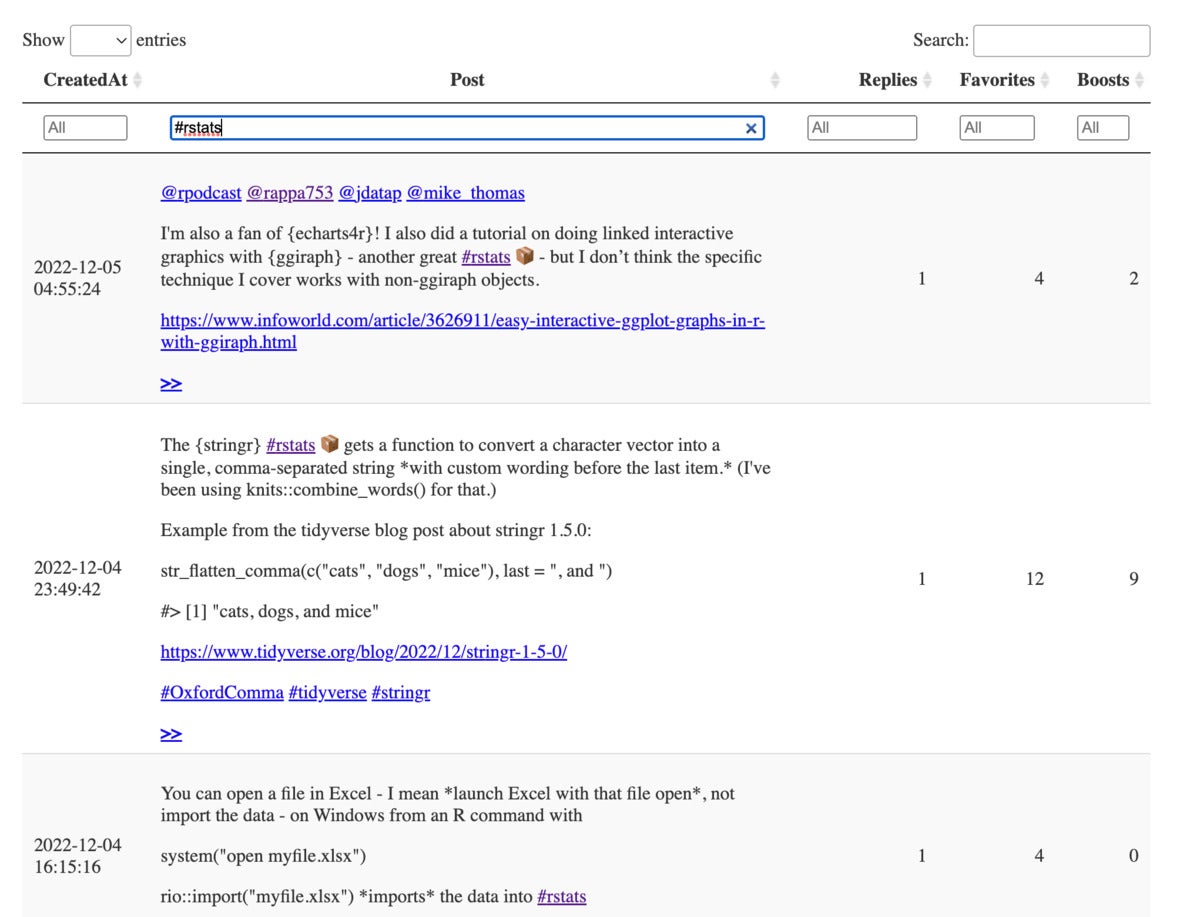
我的Mastodon帖子的互动表。此表是使用rtot使用DTR包创建的。
如何拉入新的Mastodon posts
更新数据以拉新帖子很容易,因为get_account_statuses()函数包含since_id参数。首先,从现有数据中查找最大ID:
max_id<-max(smach_statuses$id)
接下来,查找自max_id之后的所有帖子的更新:
new_statuses <- get_account_statuses(my_id, since_id = max_id,
limit = 10, verbose = TRUE)
all_statuses <- bind_rows(new_statuses, smach_statuses)
如果您想在现有数据中看到最近的一些帖子的最新参与度指标,我建议使用最后10或20篇帖子,而不是使用since_id。然后,您可以将其与现有数据相结合,并通过保留第一项来进行重复数据消除。有一种方法可以做到:
new_statuses <- get_account_statuses(my_id, limit = 25, verbose = TRUE)
all_statuses <- bind_rows(new_statuses, smach_statuses) |>
distinct(id, .keep_all = TRUE)
如何阅读下载的Mastodon存档
还有一种方法可以获取所有帖子,如果你已经在Mastodon上玩了一段时间,并且在这段时间里有很多活动,这一方法特别有用。您可以从网站下载Mastodon存档。
在Mastodon web界面中,单击左侧“设置”列上方的小齿轮图标,然后单击“导入和导出”>“数据导出”。您应该可以看到一个选项来下载文章和媒体的存档。不过,您只能每七天请求一次归档,而且它不会包含任何参与度指标。
一旦下载了存档文件,您可以手动解压缩它,或者根据我的喜好,使用存档包(CRAN上提供)提取文件。在从归档文件中提取文件之前,我还将加载jsonlite、stringr和tidyr包:
library(archive)
library(jsonlite)
library(stringr)
library(tidyr)
archive_extract("name-of-your-archive-file.tar.gz")
接下来,您需要查看outbox.json的orderItems。以下是我如何将其导入R:
my_outbox <- fromJSON("outbox.json")[["orderedItems"]]
my_posts <- my_outbox |>
unnest_wider(object, names_sep = "_")
从那里,我为一个可搜索的表创建了一个数据集,与rtot结果中的数据集类似。这个存档包括所有活动,例如喜欢另一篇文章,这就是为什么我要过滤类型Create和确保object_content有值。与之前一样,我在帖子内容中添加了一个>>可点击的URL,并调整了日期的显示方式:
search_table_data <- my_posts |>
filter(type == "Create") |>
filter(!is.na(object_content)) |>
mutate(
url = paste0("<a target = 'blank' href = '", object_url,"'><strong> >></strong></a>")
) |>
rename(CreatedAt = published, Post = object_content) |>
mutate(CreatedAt = str_replace_all(CreatedAt, "T", " "),
CreatedAt = str_replace_all(CreatedAt, "Z", " "),
Post = str_replace(Post, "<\\/p>$", " "),
Post = paste0(Post, " ", url, "</p>")
) |>
select(CreatedAt, Post) |>
arrange(desc(CreatedAt))
然后,使用DT创建可搜索表是另一个简单的单一功能:
datatable(search_table_data, rownames = FALSE, escape = FALSE,
filter = 'top', options = list(search = list(regex = TRUE)))
这对于您自己使用很方便,但我不会使用存档结果公开共享,因为其中哪些可能是私人消息不太明显(您需要对to列进行一些过滤)。
有关更多R提示,请访问InfoWorld的Do more With R页面。
- 登录 发表评论