
【LangChain】使用LangChain(而非OpenAI)回答有关文档的问题
如何使用Hugging Face LLM(开源LLM)与您的文档、PDF以及网页中的文章进行对话。
最后,这是第一步。我已经到处找了好几个月了。
所有的文章、教程和youtube视频都只教你如何使用OpenAI做事。但老实说,这相当令人沮丧。首先,所有人工智能模型的基础都来自学术界:其次,我不敢相信,当有一个大社区在幕后工作时,我们被迫去做事情。
在这里,我将展示如何在不使用OpenAI的情况下使用免费的Google Colab笔记本与任何文档交互(我将在这里介绍文本文件、pdf文件和网站url)。由于计算的限制,我们将使用Hugging Face API和完全开源的LLM来利用LangChain库与我们的文档交互。
作为指南的简介
我对文本生成背后的技术很感兴趣,作为一名工程师,我想进行实验。但作为一个人和一名教师,我认为了解人工智能的工具和思考工具更重要。
我强烈建议你阅读詹姆斯·普朗基特的精彩文章《论生成人工智能与不自由》。引用他的话:
技术真的是我们经常想象中的中立工具吗?即技术是我们发明然后决定如何使用的东西吗?
【LangChain】与文档聊天:将OpenAI与LangChain集成的终极指南
欢迎来到人工智能的迷人世界,在那里,人与机器之间的通信越来越模糊。在这篇博客文章中,我们将探索人工智能驱动交互的一个令人兴奋的新前沿:与您的文本文档聊天!借助OpenAI模型和创新的LangChain框架的强大组合,您现在可以将静态文档转化为交互式对话。
你准备好彻底改变你使用文本文件的方式了吗?然后系好安全带,深入了解我们将OpenAI与LangChain集成的终极指南,我们将一步一步地为您介绍整个过程。
什么是LangChain?
LangChain是一个强大的框架,旨在简化大型语言模型(LLM)应用程序的开发。通过为各种LLM、提示管理、链接、数据增强生成、代理编排、内存和评估提供单一通用接口,LangChain使开发人员能够将LLM与真实世界的数据和工作流无缝集成。该框架允许LLM通过合并外部数据源和编排与不同组件的交互序列,更有效地解决现实世界中的问题。
我们将在下面的示例应用程序中使用该框架从文本文档源生成嵌入,并将这些内容持久化到Chroma矢量数据库中。然后,我们将使用LangChain在后台使用OpenAI语言模型来查询用户提供的问题,以处理请求。
这将使我们能够与自己的文本文档聊天。
【LLM】微调我的第一个WizardLM LoRA
根据特定用例调整LLM的行为
之前,我写过关于与Langchain和Vicuna等当地LLM一起创建人工智能代理的文章。如果你不熟悉这个话题,并且有兴趣了解更多,我建议你阅读我之前的文章,开始学习。
今天,我将这个想法向前推进几步。
首先,我们将使用一个更强大的模型来与Langchain Zero Shot ReAct工具一起使用,即WizardLM 7b模型。
其次,我们将使用LLM中的几个提示来生成一个数据集,该数据集可用于微调任何语言模型,以了解如何使用Langchain Python REPL工具。在这个例子中,我们将使用我的羊驼lora代码库分支来微调WizardLM本身。
我们为什么要这样做?因为不幸的是,大多数模型都不擅长在Langchain库中使用更复杂的工具,我们希望对此进行改进。我们的最终目标是让本地LLM使用Langchain工具高效运行,而不需要像我们目前需要的那样进行过多提示。
总之,以下是本文的部分:
【LLM】人工智能应用构建的十大预训练NLP语言模型

在人工智能领域,自然语言处理(NLP)被广泛认为是阅读、破译、理解和理解人类语言的最重要工具。有了NLP,机器可以令人印象深刻地模仿人类的智力和能力,从文本预测到情感分析再到语音识别。
什么是自然语言处理?
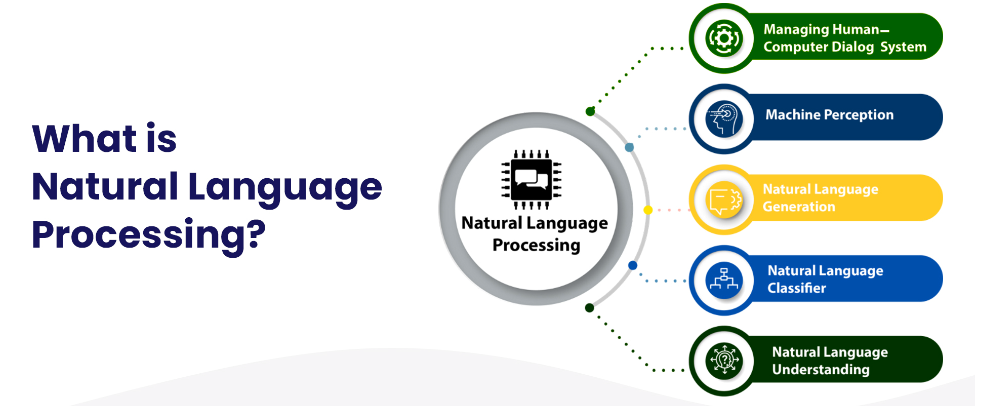
【LLM】2023年大型语言模型培训
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易,但开发一个大型语言模型需要大量的计算机科学知识、时间和资源。我们撰写这篇文章是为了让商业领袖了解:
- 大型语言模型的定义
- 大型语言模型示例
- 大型语言模型的体系结构
- 大型语言模型的训练过程,
这样他们就可以有效地利用人工智能和机器学习。
什么是大型语言模型?
大型语言模型是一种机器学习模型,它在大型文本数据语料库上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译
大型语言模型通常基于深度学习神经网络,如Transformer架构,并在大量文本数据上进行训练,通常涉及数十亿个单词。较大的模型,如谷歌的BERT模型,使用来自各种数据源的大型数据集进行训练,这使它们能够为许多任务生成输出。
如果您是大型语言模型的新手,请查看我们的“大型语言模型:2023年完整指南”文章。
【NLP】2023年改变人工智能的前六大NLP语言模型
【LLM】大型语言模型综述论文
今天我将与大家分享一篇精彩的论文。这项调查提供了LLM文献的最新综述,这对研究人员和工程师来说都是一个有用的资源。
为什么选择LLM?
当参数尺度超过一定水平时,这些扩展的语言模型不仅实现了显著的性能改进,而且还表现出一些小规模语言模型(如BERT)所不具备的特殊能力(如上下文学习)。
为了区分参数尺度的差异,研究界为显著大小的PLM(例如,包含数百亿或数千亿个参数)创造了“大型语言模型”(LLM)一词。
特别是,这里的研究人员关注LLM的四个主要方面,即预训练、适应调整、利用和能力评估。此外,他们还总结了开发LLM的可用资源,并讨论了未来方向的剩余问题。
近年来现有大型语言模型(大小大于10B)的时间表。他们用黄色标记开源LLM。

现有LLM的预训练数据中各种数据源的比率。
【LLM】大型语言模型综述
【LLM】Free Dolly:推出世界上第一个真正开放的指令调谐LLM
两周前,我们发布了Dolly,这是一个大型语言模型(LLM),经过不到30美元的训练,可以展示类似ChatGPT的人机交互(又称指令跟随)。今天,我们将发布Dolly 2.0,这是第一个开源的指令遵循LLM,它对授权用于研究和商业用途的人工生成指令数据集进行了微调。
Dolly 2.0是一个基于EleutherAI pythia模型家族的12B参数语言模型,专门针对Databricks员工众包的新的、高质量的人工生成指令跟踪数据集进行了微调。
我们正在开源Dolly 2.0的全部内容,包括训练代码、数据集和模型权重,所有这些都适合商业使用。这意味着任何组织都可以创建、拥有和定制功能强大的LLM,这些LLM可以与人对话,而无需为API访问或与第三方共享数据付费。
在Jupyter笔记本中使用Python语言链在Mac上运行GPT4All
在过去的三周左右时间里,我一直在关注本地运行的大型语言模型(LLM)的疯狂开发速度,从llama.cpp开始,然后是alpaca,最近是(?!)gpt4all。
在那段时间里,我的笔记本电脑(2015年年中的Macbook Pro,16GB)在修理厂里呆了一个多星期,直到现在我才真正有了一个快速的游戏机会,尽管我10天前就知道我想尝试什么样的东西,而这在过去几天才真正成为可能。
根据这个要点,以下脚本可以作为Jupyter笔记本下载 this gist.