
【langchain】在单个文档知识源的上下文中使用langchain对GPT4All运行查询
In the previous post, Running GPT4All On a Mac Using Python langchain in a Jupyter Notebook, 我发布了一个简单的演练,让GPT4All使用langchain在2015年年中的16GB Macbook Pro上本地运行。在这篇文章中,我将提供一个简单的食谱,展示我们如何运行一个查询,该查询通过从单个基于文档的已知源检索的上下文进行扩展。
I’ve updated the previously shared notebook here to include the following…
基于文档的知识源支持的示例查询
使用langchain文档中的示例进行示例文档查询。
【ChatGPT】提示设计的艺术:使用清晰的语法
探索清晰的语法如何使您能够将意图传达给语言模型,并帮助确保输出易于解析

这是与Marco Tulio Ribeiro共同撰写的关于如何使用指导来控制大型语言模型(LLM)的系列文章的第一部分。我们将从基础知识开始,逐步深入到更高级的主题。
在这篇文章中,我们将展示清楚的语法使您能够向LLM传达您的意图,并确保输出易于解析(如保证有效的JSON)。为了清晰和再现性,我们将从开源的StableLM模型开始,无需微调。然后,我们将展示相同的想法如何应用于像ChatGPT/GPT-4这样的微调模型。下面的所有代码都可以放在笔记本上,如果你愿意的话可以复制。
【LLM】LangChain 资料大全
【LLM】LangChian自动评估( Auto-Evaluator )机会
编者按:这是兰斯·马丁的一篇客座博客文章。
TL;DR
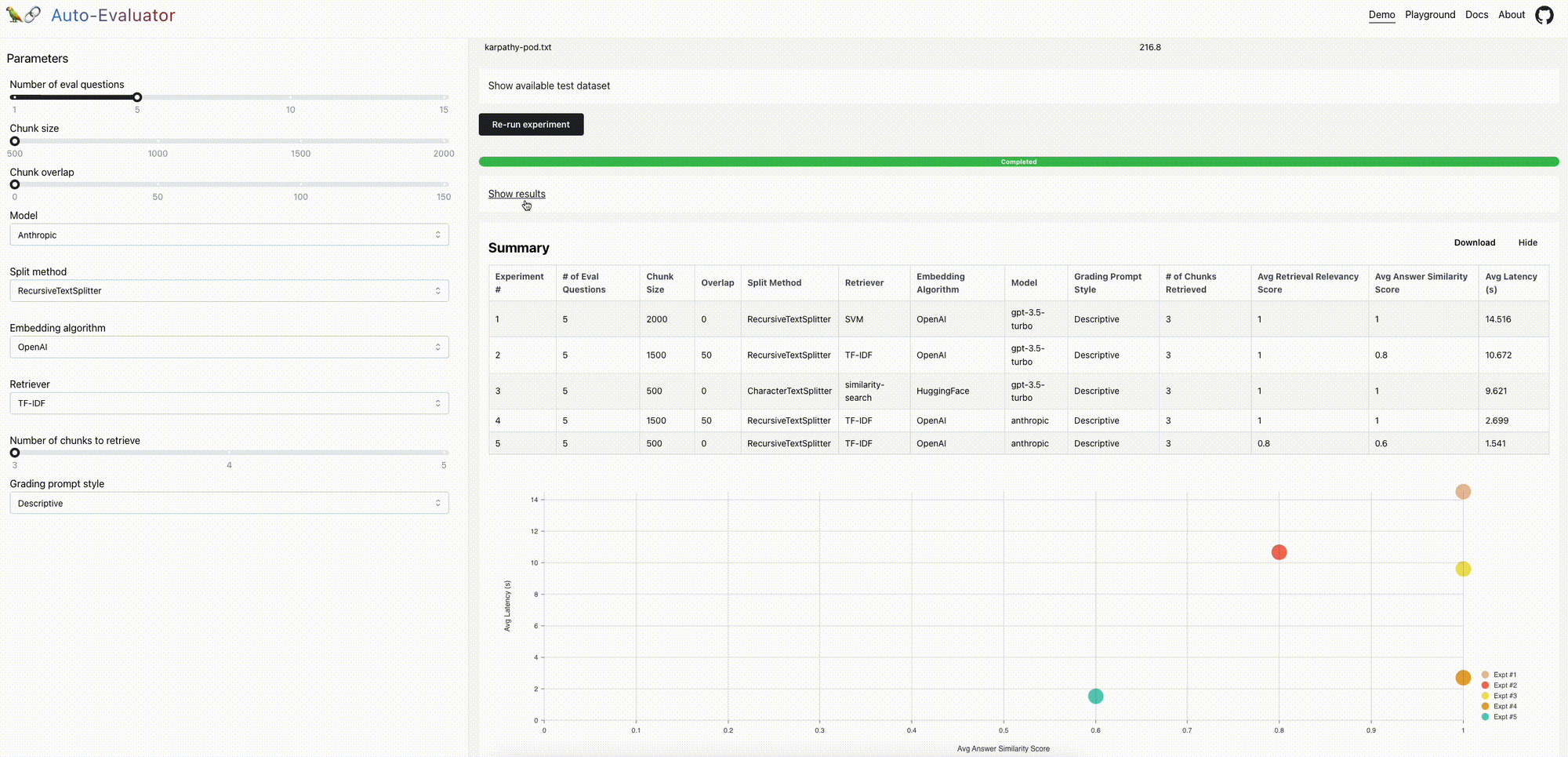
我们最近开源了一个自动评估工具,用于对LLM问答链进行评分。我们现在发布了一个开源、免费的托管应用程序和API,以扩展可用性。下面我们将讨论一些进一步改进的机会。
上下文
文档问答是一个流行的LLM用例。LangChain可以轻松地将LLM组件(例如,模型和检索器)组装成支持问答的链:输入文档被分割成块并存储在检索器中,在给定用户问题的情况下检索相关块并传递给LLM以合成答案。
问题
质量保证系统的质量可能有很大差异;我们已经看到由于特定的参数设置而产生幻觉和回答质量差的情况。但是,(1)评估答案质量和(2)使用此评估来指导改进的QA链设置(例如,块大小、检索到的文档数)或组件(例如,模型或检索器选择)并不总是显而易见的。
【LangChain 】LangChain 计划和执行代理
TL;DR:我们正在引入一种新型的代理执行器,我们称之为“计划和执行”。这是为了与我们以前支持的代理类型形成对比,我们称之为“Action”代理。计划和执行代理在很大程度上受到了BabyAGI和最近的计划和解决论文的启发。我们认为Plan and Execute非常适合更复杂的长期规划,但代价是需要调用更多的语言模型。我们正在将其初始版本放入实验模块,因为我们预计会有快速的变化。
链接:
到目前为止,LangChain中的所有代理都遵循ReAct文件开创的框架。让我们称之为“行动特工”。这些算法可以大致用以下伪代码表示:
【LLM】LangChain 的Callbacks 改进
TL;DR:我们宣布对我们的回调系统进行改进,该系统支持日志记录、跟踪、流输出和一些很棒的第三方集成。这将更好地支持具有独立回调的并发运行,跟踪深度嵌套的LangChain组件树,以及范围为单个请求的回调处理程序(这对于在服务器上部署LangChain非常有用)。
【LLM】利用并行LLM Agent Actor Trees释放AI协作的力量
编者按:以下是赛勒斯在 Shaman AI的客座博客文章。我们使用客座博客文章来突出有趣和新颖的应用程序,当然是这样。最近有很多关于经纪人的讨论,但大多数都是围绕一个经纪人展开的。如果涉及多个代理,则会依次调用它们。这部作品很新颖,因为它突破了这一界限,探索了多个平行行动的代理。
重要链接:
介绍
近年来,人工智能领域取得了重大进展,人工智能代理现在能够处理复杂的任务。尽管取得了这些进展,但有效地并行和协调多个人工智能代理协同工作仍然是一个挑战。引入Agent Actors-这是一个突破性的解决方案,使开发人员能够创建和管理人工智能代理树,这些代理使用Actor并发模型在复杂任务上进行协作。
在这篇博客文章中,我们将探讨并发的参与者模型、代理参与者的关键功能、它所带来的可能性,以及如何开始构建自己的代理树。我们希望激励LLM社区尝试新的自引用LLM架构。
【LLM】LangChain整合Gradio和LLM代理
编者按:这是Gradio的软件工程师Freddy Boulton的一篇客座博客文章。我们很高兴能分享这篇文章,因为它为生态系统带来了大量令人兴奋的新工具。代理在很大程度上是由他们所拥有的工具定义的,所以能够为他们配备所有这些gradio_tools对我们来说是非常令人兴奋的!
重要链接:
大型语言模型(LLM)给人留下了深刻的印象,但如果我们能赋予它们完成专门任务的技能,它们可以变得更加强大。
【LLM】RecAlign-社交媒体订阅源的智能内容过滤器
【编者按】这是田进的客串文章。我们强调这个应用程序,因为我们认为它是一个新颖的用例。具体而言,我们认为推荐系统在我们的日常生活中具有难以置信的影响力,关于LLM将如何影响这些系统,目前还没有大量的讨论。
我们都经历过使用推荐系统的痛苦:你注册了推特来跟上最新的人工智能研究,但点击一个有趣的模因会让你的时间线充满类似的分心。这些系统的作用是最大限度地提高所有者的利润,而不是你的福利。在这里,我们概述了我们以LangChain为动力的解决方案背后的基本原理,以解决其核心问题。
透明度和可配置性。
在布莱恩·克里斯蒂安(Brian Christian)的《结盟问题》(the Alignment Problem)一书中,他分享了一则轶事:他的朋友正在从酒精成瘾中恢复,但推荐系统可能有点太了解他对酒精的热爱,并在他的推送中充斥着酒精广告。这一集生动地说明了一个反复出现的问题——推荐系统善于迎合我们今天的样子,但几乎没有给我们留下什么自由来决定我们想要成为什么样的人。目前的推荐系统缺乏透明度和可配置性。因此,我们很难识别推荐系统对我们的偏好做出的任何有问题的推断,更不用说修改它们了。
【LLM】LangChain 利用上下文压缩改进文档检索
注意:这篇文章假设你对LangChain有一定的熟悉程度,并且是适度的技术性文章。
💡 TL;DR:我们引入了新的抽象和新的文档检索器,以便于对检索到的文档进行后处理。具体来说,新的抽象使得获取一组检索到的文档并仅从中提取与给定查询相关的信息变得容易。
介绍
许多LLM支持的应用程序需要一些可查询的文档存储,以便检索尚未烘焙到LLM中的特定于应用程序的信息。
假设你想创建一个聊天机器人,可以回答有关你个人笔记的问题。一种简单的方法是将笔记嵌入大小相等的块中,并将嵌入的内容存储在向量存储中。当你问系统一个问题时,它会嵌入你的问题,在向量存储中执行相似性搜索,检索最相关的文档(文本块),并将它们附加到LLM提示中。
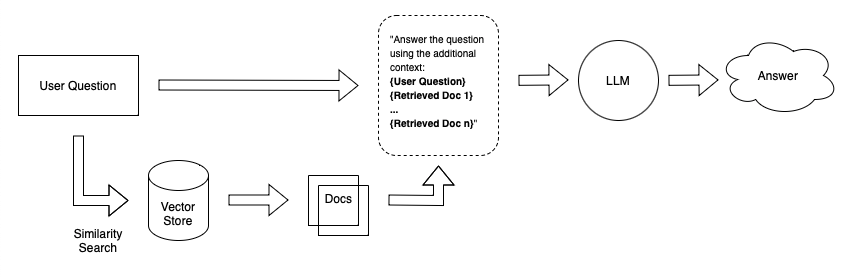
A simple retrieval Q&A system