
数据建模主要由人类专家进行,包括拥有专业知识和技能的数据架构师、数据建模者和分析师。然而,人工智能的最新进展,特别是在自然语言处理(NLP)和大型语言模型(LLM)方面,引发了人们对其对该领域潜在影响的讨论。作为一名数据爱好者,这让我思考我能在多大程度上突破这些新的人工智能功能的界限,尤其是使用ChatGPT。我决定进行一系列实验来探索各种可能性。
在我实验的最初阶段,我的重点将是手动执行任务和流程,而不是依赖自动化。通过采用这种实践方法,我的目标是全面了解与主题相关的概念、方法和挑战。此外,它将使我能够收集有价值的见解和反馈,这些见解和反馈可以指导未来关于自动化的决策。通过这项手动工作,我的目标是获得可用于评估集成自动化的实用性和优势的知识和经验。
如果你是数据建模领域的新手,我邀请你阅读我关于数据建模在人工智能时代的重要性的另一篇文章。你可以在以下链接找到:数据建模在AI时代的重要性
入门:
获取ChatGPT登录。
访问chat.OpenAi.com,注册一个带有电子邮件地址的帐户或谷歌或微软帐户。您必须创建一个OpenAI网站帐户才能登录并访问ChatGPT。这是一张令人惊叹的截图中的“聊天GPT登录终极指南”。
获取所需的数据。
我将使用这个Kaggle开放数据集提供的数据,如果你打算继续,你需要将数据下载到你的本地机器上。人力资源案例研究需要以下CSV/数据集。CSV
先进的快速工程。
我们将首先创建精心制作的提示,并利用ChatGPT分析上一步下载的样本数据。这一分析将使我们能够提取数据中存在的重要概念。然后,我们可以构建我们的概念、逻辑和物理数据模型。
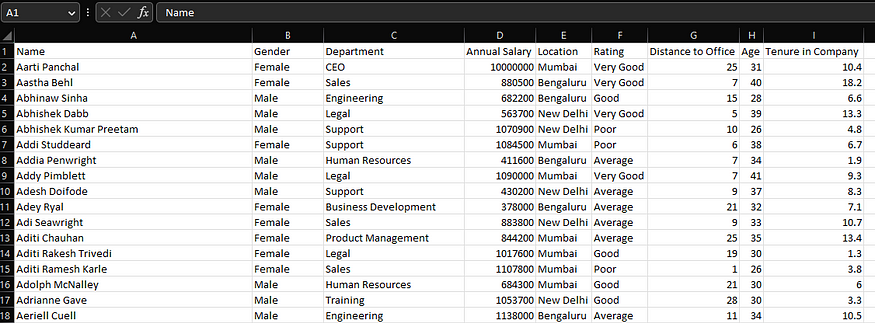
Sample data from “HR Case Study”
精心制作的提示
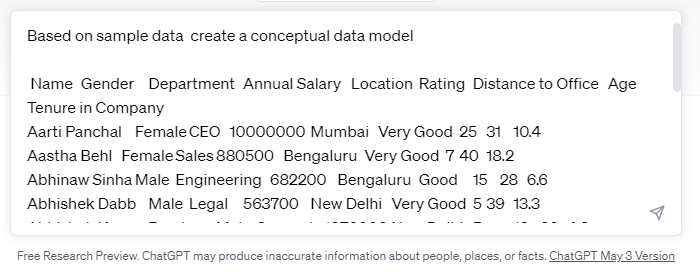
well-crafted prompts with Sample data
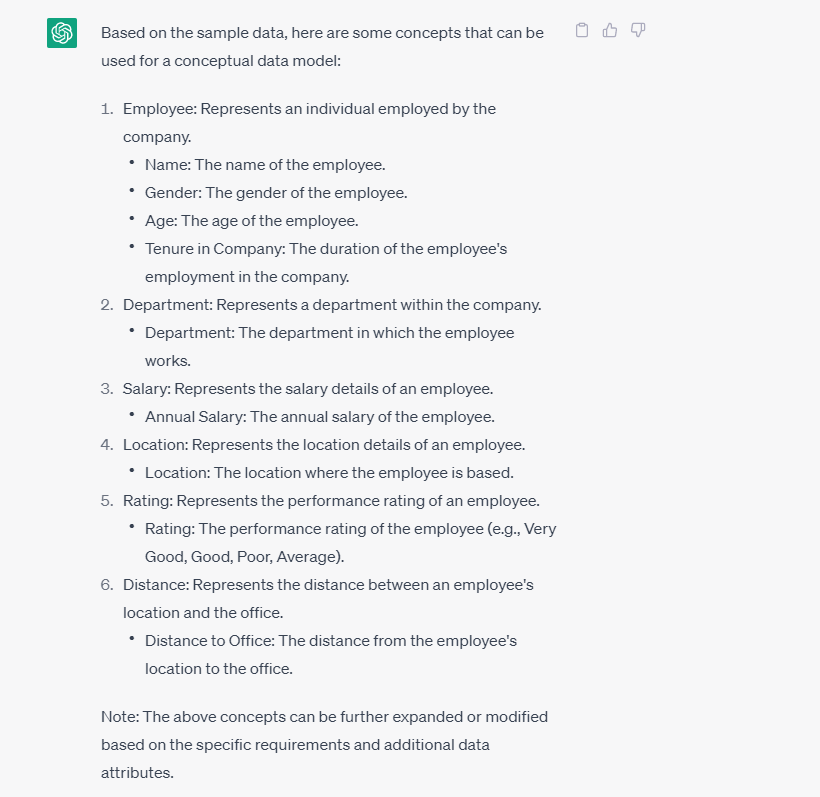
results of well-crafted prompts with Sample data
我能够利用上面的信息对这些概念进行直观的可视化。
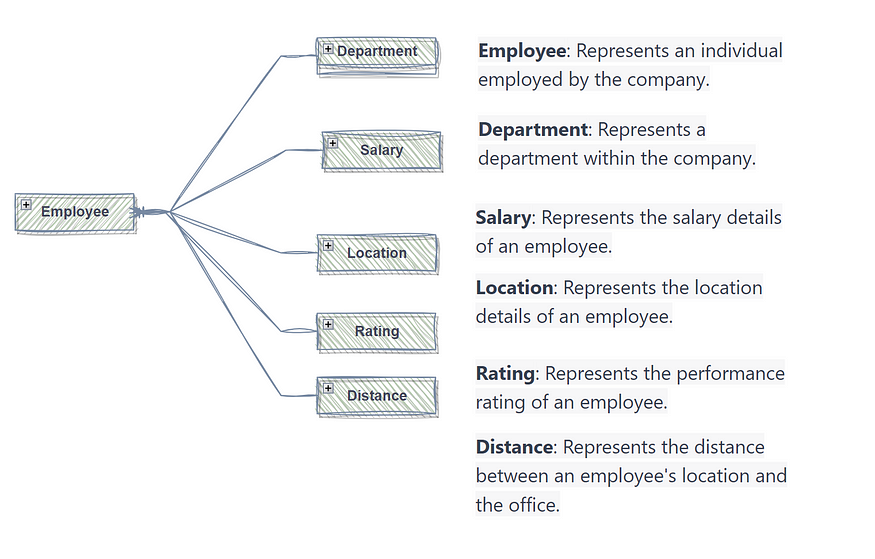
Conceptual Data Model as a result of well-crafted prompts with Sample data
随后,我请求chatgpt生成一个逻辑模型;然而,它未能将距离和位置作为概念来识别。因此,我不得不明确指示它将这两个概念合并为一个逻辑实体,并将距离视为一个属性。
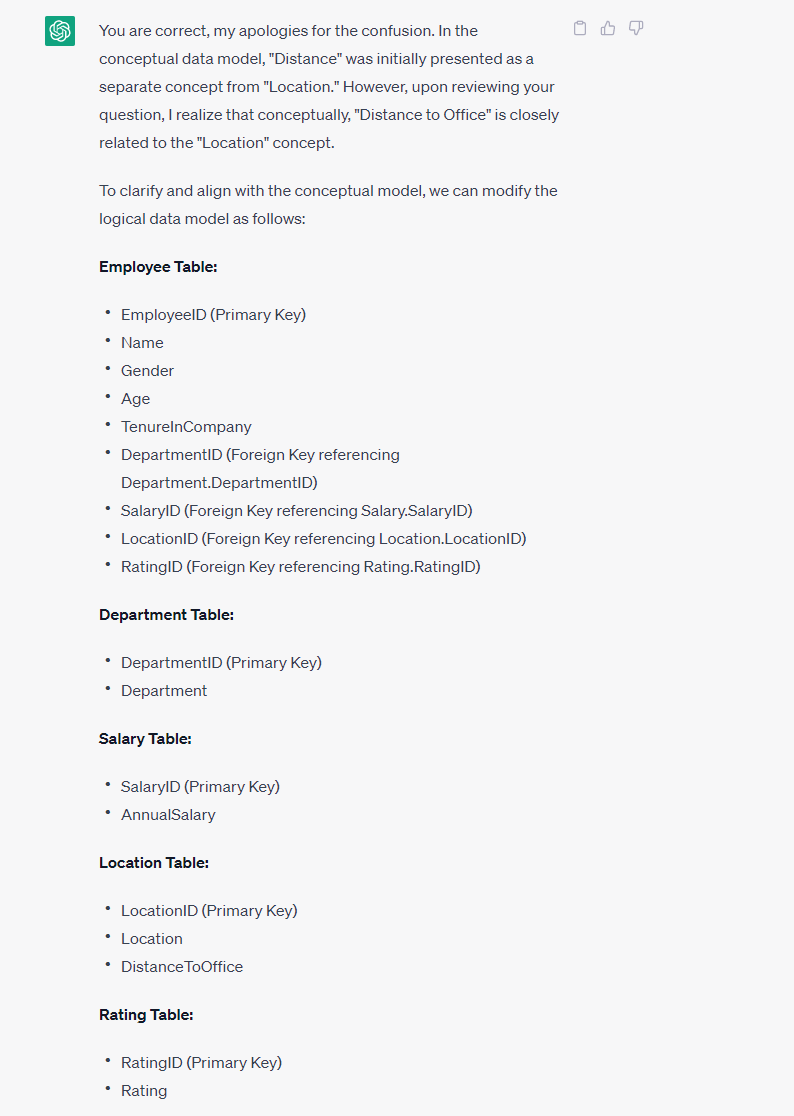
尽管产生了令人满意的结果,但GPT忽略了一个小细节:基数。我不得不把它作为我精心制作的提示的一部分,ChatGPT自我救赎了。

result from a well-crafted prompt requesting cardinality
我再一次成功地将这些概念清晰简洁地形象化了。
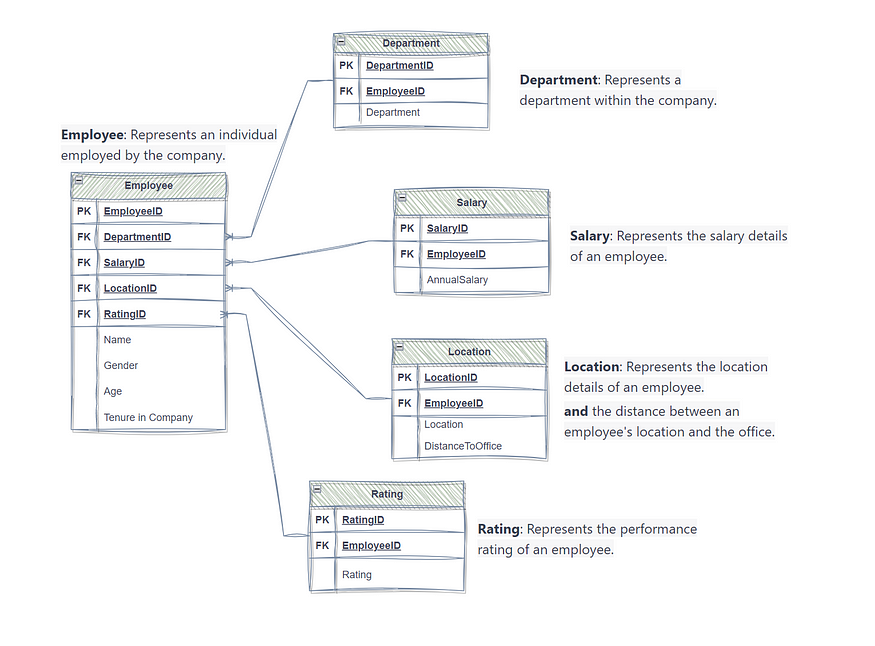
visual Logical Data Model as a result of well-crafted prompts (explicit this time round)
考虑到它适用于分析,我决定使用维度模型作为物理数据模型。此外,我是使用维度模型的坚定支持者。为了简化数据分析,我要求在我的维度中包含更改跟踪。此外,我特别要求为评级维度实现SCD Type 4,因为与其他维度相比,它有可能发生更频繁的变化。最后,我表示希望随时了解银行假期的情况。
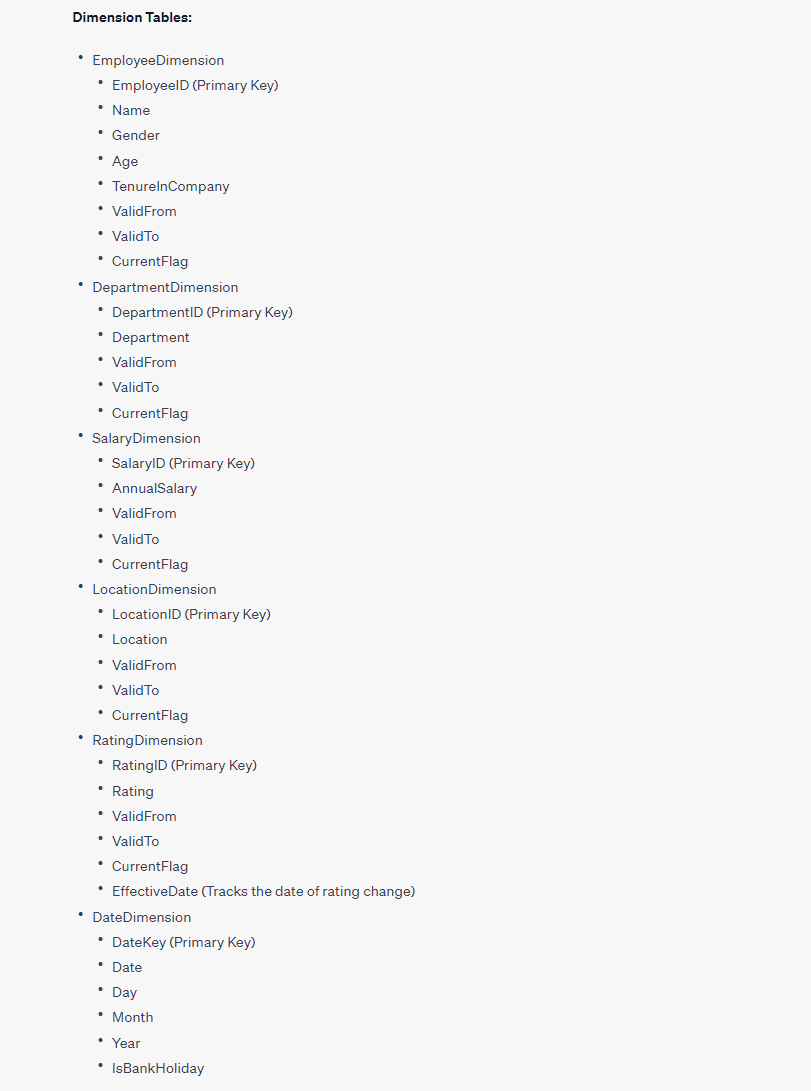 Physical (dimensional) Data Model as a result of well-crafted prompts
Physical (dimensional) Data Model as a result of well-crafted prompts Physical (Fact) Data Model as a result of well-crafted prompts
Physical (Fact) Data Model as a result of well-crafted prompts 我再一次成功地将维度数据模型可视化。
我再一次成功地将维度数据模型可视化。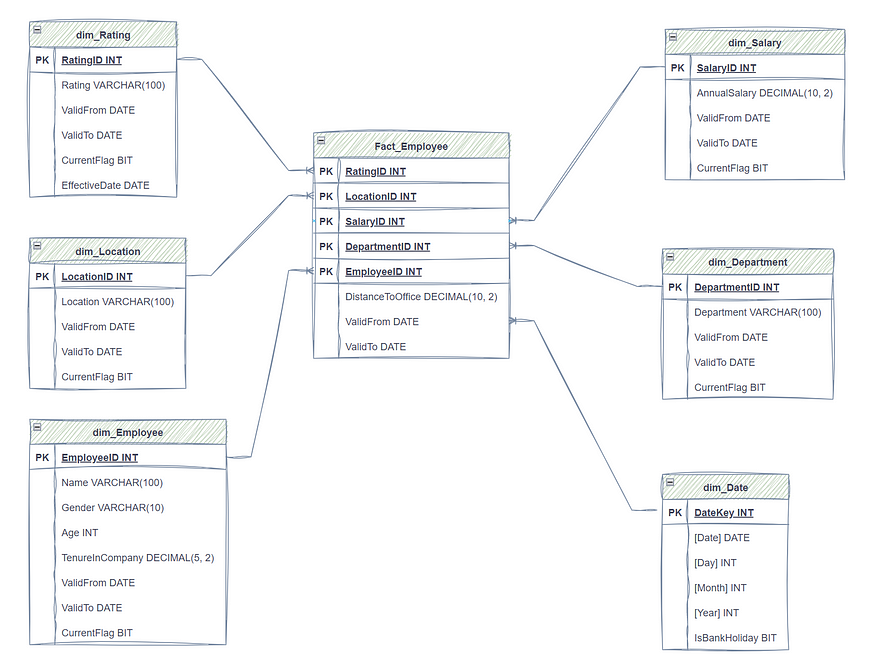 我请求GPT生成脚本,用于创建以SQL Server作为目标数据库的模型。GPT再一次成功地交付了所需的结果。
我请求GPT生成脚本,用于创建以SQL Server作为目标数据库的模型。GPT再一次成功地交付了所需的结果。
-- Create Dimension Tables
CREATE TABLE dim_Employee (
EmployeeID INT PRIMARY KEY,
Name VARCHAR(100),
Gender VARCHAR(10),
Age INT,
TenureInCompany DECIMAL(5, 2),
ValidFrom DATE,
ValidTo DATE,
CurrentFlag BIT
);
CREATE TABLE dim_Department (
DepartmentID INT PRIMARY KEY,
Department VARCHAR(100),
ValidFrom DATE,
ValidTo DATE,
CurrentFlag BIT
);
CREATE TABLE dim_Salary (
SalaryID INT PRIMARY KEY,
AnnualSalary DECIMAL(10, 2),
ValidFrom DATE,
ValidTo DATE,
CurrentFlag BIT
);
CREATE TABLE dim_Location (
LocationID INT PRIMARY KEY,
Location VARCHAR(100),
ValidFrom DATE,
ValidTo DATE,
CurrentFlag BIT
);
CREATE TABLE dim_Rating (
RatingID INT PRIMARY KEY,
Rating VARCHAR(100),
ValidFrom DATE,
ValidTo DATE,
CurrentFlag BIT,
EffectiveDate DATE
);
CREATE TABLE dim_Date (
DateKey INT PRIMARY KEY,
[Date] DATE,
[Day] INT,
[Month] INT,
[Year] INT,
IsBankHoliday BIT
);
-- Create Fact Table
CREATE TABLE Fact_Employee (
EmployeeID INT,
DepartmentID INT,
SalaryID INT,
LocationID INT,
RatingID INT,
DistanceToOffice DECIMAL(10, 2),
ValidFrom DATE,
ValidTo DATE
);
-- Add foreign key constraints
ALTER TABLE Fact_Employee
ADD CONSTRAINT FK_Fact_Employee_dim_Employee FOREIGN KEY (EmployeeID)
REFERENCES dim_Employee (EmployeeID);
ALTER TABLE Fact_Employee
ADD CONSTRAINT FK_Fact_Employee_dim_Department FOREIGN KEY (DepartmentID)
REFERENCES dim_Department (DepartmentID);
ALTER TABLE Fact_Employee
ADD CONSTRAINT FK_Fact_Employee_dim_Salary FOREIGN KEY (SalaryID)
REFERENCES dim_Salary (SalaryID);
ALTER TABLE Fact_Employee
ADD CONSTRAINT FK_Fact_Employee_dim_Location FOREIGN KEY (LocationID)
REFERENCES dim_Location (LocationID);
ALTER TABLE Fact_Employee
ADD CONSTRAINT FK_Fact_Employee_dim_Rating FOREIGN KEY (RatingID)
REFERENCES dim_Rating (RatingID);
结论
最后,我对ChatGPT的表现感到惊喜。这超出了我的预期。通过少量的数据,ChatGPT对数据以及一切是如何连接的表现出了非凡的理解。我能够创建一个概念数据模型,一个解释数据概念的逻辑数据模型,甚至是我选择的物理数据模型。在有限的信息中看到如此高水平的理解是很有趣的。 在接下来的实验阶段(第2部分:接下来的标题),我将创建实际的物理数据模型。我将用电子表格中的数据填充模型,也许可以开始探索自动化(ETL)。
- 登录 发表评论