标记单词的顺序-简洁明了。

Figure 1: Colour-coded recognised entities
这篇文章假设读者对从文本中提取实体有一些概念,并希望进一步了解新的自定义实体识别的最先进技术以及如何使用这些技术。然而,如果你是NER问题的新手,请在这里阅读。
话虽如此,这篇文章的目的是描述spaCy的预训练自然语言处理(NLP)核心模型用于学习识别新实体的使用。来自spacy的现有核心NLP模型被训练来识别各种实体,如图2所示。
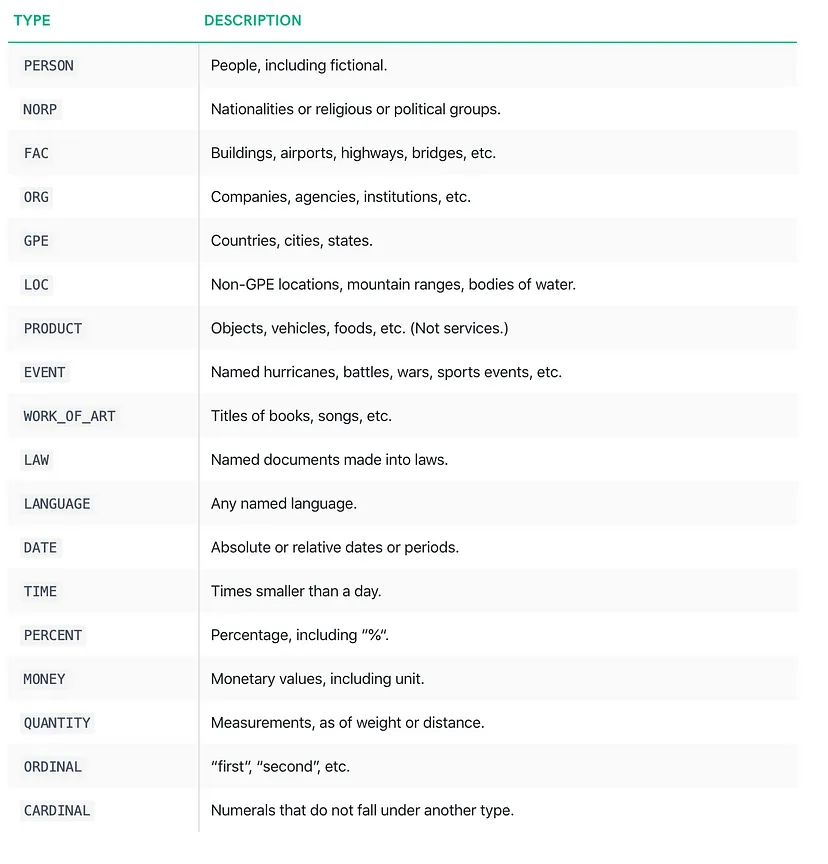
Figure 2: Existing entity recognised by spaCy core models (source)
尽管如此,用户可能希望构建自己的实体来解决问题需求。在这种情况下,预先存在的实体会使自己变得不足,因此,需要训练NLP模型来完成这项工作。感谢spaCy的文档和预训练模型,这不是很困难。
如果你不想进一步阅读,而是想学习如何使用它,那么请使用这款jupyter笔记本——它是独立的。无论如何,我也建议浏览一下。
数据预处理
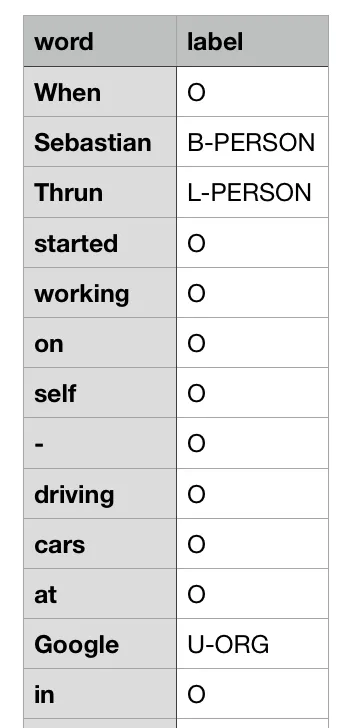
就像任何需要输入和输出才能学习的监督学习算法一样,类似地,这里的输入是文本,输出是根据BILOO编码的,如图3所示。然而,尽管存在不同的方案,Ratinov和Roth表明,最小Begin,In,Out(IOB)方案比明确标记边界令牌的BILOO方案更难学习。spaCy提供了一个IOB编码的例子,我发现它与所提供的参数一致。因此,从这里开始,任何提及注释方案的内容都将是BILOO。

Figure 3: BILUO scheme
下图显示了BILOO编码实体的简短示例。
要用BILOO方案对您进行编码,有三种可能的方法。其中一种方法是创建一个spaCy-doc表单文本字符串,并将从doc中提取的令牌保存在用新行分隔的文本文件中。然后根据BILOO方案对每个令牌进行标记。人们可以创建自己的令牌并对其进行标记,但可能会降低性能——稍后将对此进行详细介绍。以下是如何标记您的数据,以便以后在NER培训中使用。
import spacy
import numpy as np
import pandas as pd
nlp = spacy.load('en')
text = ("When Sebastian Thrun started working on self-driving cars at "
"Google in 2007, few people outside of the company took him "
"seriously. “I can tell you very senior CEOs of major American "
"car companies would shake my hand and turn away because I wasn’t "
"worth talking to,” said Thrun, in an interview with Recode earlier "
"this week.")
doc = nlp(text)
words = []
labels = []
for token in doc:
words.append(token.text)
labels.append('O') # As most of token will be non-entity (OUT). Replace this later with actual entity a/c the scheme.
df = pd.DataFrame({'word': words, 'label': labels})
df.to_csv('ner-token-per-line.biluo', index=False) # biluo in extension to indicate the type of encoding, it is ok to keep csv
上面的片段使注释变得更容易,但这不能直接输入到spaCy模型中进行学习。尽管如此,spaCy提供的另一个模块GoldParse解析模型所接受的保存格式。使用下面的snipped从保存的文件中读取数据,并将其解析为模型接受的形式。
dpath = 'ner-token-per-line.biluo' df = pd.read_csv(dpath, sep=',') words = df.word.values ents = df.label.values text = ' '.join(words) from spacy.gold import GoldParse doc = nlp.make_doc(text) g = GoldParse(doc, entities=ents) X = [doc] Y = [g]
另一种方式是使用每个实体/标签的偏移索引,即实体的开始和结束(即,实体的开始、内部、最后部分结合在一起)的索引与标签一起提供,例如:
text = ("When Sebastian Thrun started working on self-driving cars at "
"Google in 2007, few people outside of the company took him "
"seriously. “I can tell you very senior CEOs of major American "
"car companies would shake my hand and turn away because I wasn’t "
"worth talking to,” said Thrun, in an interview with Recode earlier "
"this week.")
g = {'entities': [(5, 20, 'PERSON'), (61, 67, 'ORG'), (71, 75, 'DATE'), (173, 181, 'NORP'),
(271, 276, 'PERSON'), (299, 305, 'ORG'), (306, 323, 'DATED')]}
X = [text]
Y = [g]
第三个与第一个类似,只是在这里我们可以修复自己的令牌并标记它们,而不是用NLP模型生成令牌然后标记它们。然而,在我的实验中,虽然这也可以起作用,但我发现这会降低性能。尽管如此,以下是您可以做到的方法:
# words = <list of user token> for example space splitted tokens spaces = [True]*len(words) spaces[-1] = False # so remove space in last doc = Doc(nlp.vocab, words=words, spaces=spaces) # Custom Doc g = GoldParse(doc, entities=ents) X = [doc] Y = [g]
训练
在对数据进行预处理并准备好进行训练后,我们需要在模型NER管道中进一步添加新实体的词汇表。核心spaCy模型有三个管道:Tagger、Parser和NER。此外,我们需要禁用标记器和解析器管道,因为我们将只训练NER管道,尽管可以同时训练所有其他管道。点击此处了解更多信息。
add_ents = ['DATED'] # The new entity
# Piplines in core pretrained model are tagger, parser, ner. Create new if blank model is to be trained using `spacy.blank('en')` else get the existing one.
if "ner" not in nlp.pipe_names:
ner = nlp.create_pipe("ner") # "architecture": "ensemble" simple_cnn ensemble, bow # https://spacy.io/api/annotation
nlp.add_pipe(ner)
else:
ner = nlp.get_pipe("ner")
prev_ents = ner.move_names # All the existing entities recognised by the model
print('[Existing Entities] = ', ner.move_names)
for ent in add_ents:
ner.add_label(ent)
new_ents = ner.move_names
# print('\n[All Entities] = ', ner.move_names)
print('\n\n[New Entities] = ', list(set(new_ents) - set(prev_ents)))
## Training
model = None # Since we are training a fresh model not a saved model
n_iter = 20
with nlp.disable_pipes(*other_pipes): # only train ner
# optimizer = nlp.begin_training()
if model is None:
optimizer = nlp.begin_training()
else:
optimizer = nlp.resume_training()
for i in range(n_iter):
losses = {}
nlp.update(X, Y, sgd=optimizer, drop=0.0, losses=losses)
# nlp.entity.update(d, g)
print("Losses", losses)
在这里,对于训练,丢弃被指定为0.0,以故意过度拟合模型,并表明它可以学习识别所有新实体。
推论
训练模型的结果:
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
# Output
Sebastian Thrun PERSON
Google ORG
2007 DATE
American NORP
Thrun PERSON
Recode ORG
earlier this week. DATED
spaCy还提供了一种生成颜色编码实体的方法(如图1所示),可以使用以下片段在web浏览器或笔记本电脑中查看这些实体:
from spacy import displacydisplacy.render(doc, style="ent") # if from notebook else displacy.serve(doc, style="ent") generally
注意事项
这里提供的培训新实体的过程可能看起来有点容易,但它确实带来了警告。在训练时,新训练的模型可能会忘记识别旧实体,因此,强烈建议将一些文本与先前训练的实体中的实体混合,除非旧实体对解决问题并不重要。其次,学习更具体的实体可能比学习广义实体更好。
结论
我们看到,开始学习新的实体并不难,但人们确实需要尝试不同的注释技术,并选择最适合给定问题的方法。
其他注意事项
- 这篇文章进一步扩展了spaCy在这里提供的例子。
- 整个代码块可以在这个jupyter笔记本中访问。自述文件还包含如何安装spaCy库以及在安装和加载预训练模型期间调试错误问题。
- 阅读Akbik等人的这篇论文。它应该有助于理解序列标记背后的算法,即多个单词实体。
- 登录 发表评论