category
We can expect it to be released in November, maybe on the 2nd anniversary of the legendary ChatGPT launch
In similar timeframes, we will also be getting Gemini 2 Ultra, LLaMA-3, Claude-3, Mistral-2 and many other groundbreaking models
(Google’s Gemini already seems to be giving tough competition to GPT-4 turbo)
It is almost certain that GPT-5 will be released incrementally, these will be the intermediate checkpoints during the training of the model
The actual training may take 3 months with extra 6 months for the security testing.
To put GPT-5 in perspective
Let us first take a look at GPT-4 Specs:
GPT4 Model Estimates
Scale: GPT-4 has ~1.8 trillion parameters across 120 layers, which is over 10 times larger than GPT-3.
Mixture Of Experts (MoE): OpenAI utilizes 16 experts within their model, each with ~111B parameters for MLP.
Dataset: GPT-4 is trained on ~13T tokens, including both text-based and code-based data, with some fine-tuning data from ScaleAI and internally.
Dataset Mixture: The training data included CommonCrawl & RefinedWeb, totalling 13T tokens. Speculation suggests additional sources like Twitter, Reddit, YouTube, and a large collection of textbooks.
Training Cost: The training costs for GPT-4 were around $63 million, taking into account the computational power required and the time of training.
Inference Cost: GPT-4 costs 3 times more than the 175B parameter Davinci, due to the larger clusters required and lower utilization rates.
Inference Architecture: The inference runs on a cluster of 128 GPUs, using 8-way tensor parallelism and 16-way pipeline parallelism.
Vision Multi-Modal: GPT-4 includes a vision encoder for autonomous agents to read web pages and transcribe images and videos. This adds more parameters on top and it is fine-tuned with another ~2 trillion tokens.
Now, GPT-5 might have 10 times the parameters of GPT-4 and this is HUGE! This means larger embedding dimensions, more layers and double the number of experts.
A bigger embedding dimension means more granularity and doubling the number of layers allows the model to develop deeper pattern recognition.
GPT-5 will be much better at reasoning, it will lay out its reasoning steps before solving a challenge and have each of those reasoning steps checked internally or externally.
The approach of verifying the reasoning steps and sampling up to 10,000 times will lead to dramatically better results in Code Generation and Mathematics.
comparison of outcome-supervised and process-supervised reward models, evaluated by their ability to search over many test solutions.
Sampling the model thousands of times and taking the answer that had the highest-rated reasoning steps doubled the performance in mathematics and no this didn’t just work for mathematics it had dramatic results across the STEM fields
GPT-5 will also be trained on much more data, both in terms of Volume, Quality and Diversity.
This includes humongous amounts of Text, Image, Audio and Video data. Also Multilingual Data and Reasoning Data
This means Multimodality will get much better this year while LLM reasoning takes off
This will make GPT-5 more agentic, just like using an LLM as an Operating System
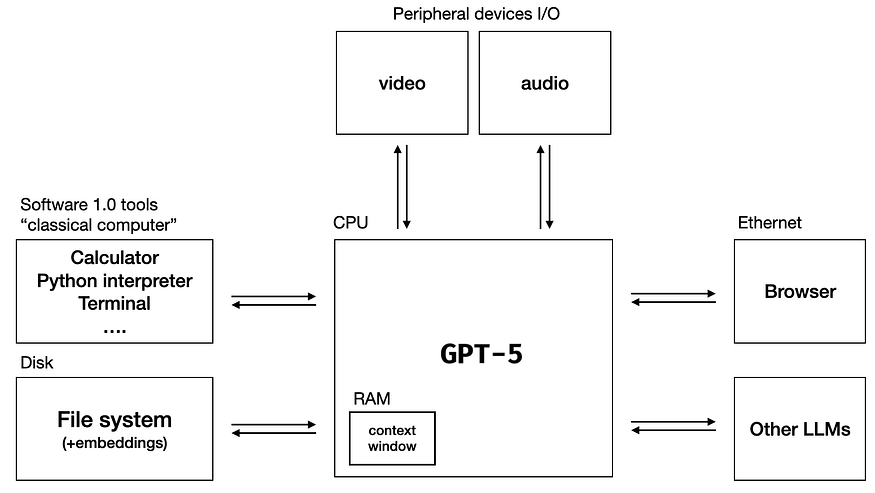
Although nothing truly insane/reality-bending will happen with LLM released in 2024 like LLMs inventing new science or curing diseases, making Dyson Spheres or Bioweapons
2024 will be crisper and more commercially applicable versions of the models that exist today and people will be surprised to see how good these models have gotten
No one truly knows how newer models will be.
The biggest theme in the history of AI is that it’s full of surprises.
Every time you think you know something you scale it up 10x and it turns out you knew nothing. We as Humanity as a species are really exploring this together
Nonetheless, all of the collective progress in LLMs and AI is a step forward towards AGI🚀
Sources:
- GPT-5: Everything You Need to Know So Far
- Visualizing the size of Large Language Models
- GPT-4 architecture, datasets, costs and more leaked
- LLM OS
- Let’s Verify Step by Step Paper
- 登录 发表评论