
category

In the rapidly evolving landscape of technology, Generative AI stands as a revolutionary force, transforming how developers & AI/ML engineers approach complex problems and innovate. This article delves into the world of Generative AI, uncovering frameworks and tools that are essential for every developer.
LangChain

Developed by Harrison Chase and debuted in October 2022, LangChain serves as an open-source platform designed for constructing sturdy applications powered by LLMs, such as chatbots like ChatGPT and various tailor-made applications.
LangChain seeks to equip data engineers with an all-encompassing toolkit for utilizing LLMs in diverse use cases, including chatbots, automated question answering, text summarization and beyond.
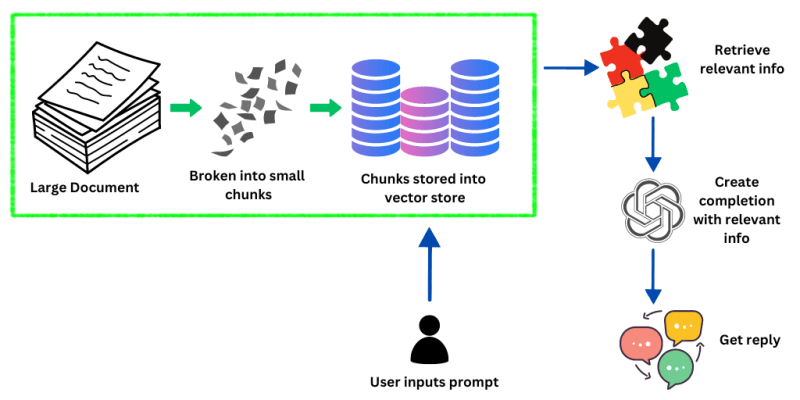
The above image shows how LangChain handles and processes information to respond to user prompts. Initially, the system starts with a large document containing a vast array of data. This document is then broken down into smaller, more manageable chunks.
These chunks are subsequently embedded into vectors — a process that transforms the data into a format that can be quickly and efficiently retrieved by the system. These vectors are stored in a vector store, essentially a database optimized for handling vectorized data.
When a user inputs a prompt into the system, LangChain queries this vector store to find information that closely matches or is relevant to the user’s request. The system employs large LLMs to understand the context and intent of the user’s prompt, which guides the retrieval of pertinent information from the vector store.
Once the relevant information is identified, the LLM uses it to generate or complete an answer that accurately addresses the query. This final step culminates in the user receiving a tailored response, which is the output of the system’s data processing and language generation capabilities.
SingleStore Notebooks

SingleStore Notebook, based on Jupyter Notebook, is an innovative tool that significantly enhances the data exploration and analysis process, particularly for those working with SingleStore’s distributed SQL database. Its integration with Jupyter Notebook makes it a familiar and powerful platform for data scientists and professionals. Here’s a summary of its key features and benefits:
- Native SingleStore SQL Support: This feature simplifies the process of querying SingleStore’s distributed SQL database directly from the notebook. It eliminates the need for complex connection strings, offering a more secure and straightforward method for data exploration and analysis.
- SQL/Python Interoperability: This allows for seamless integration between SQL queries and Python code. Users can execute SQL queries in the notebook and use the results directly in Python data frames, and vice versa. This interoperability is essential for efficient data manipulation and analysis.
- Collaborative Workflows: The notebook supports sharing and collaborative editing, enabling team members to work together on data analysis projects. This feature enhances the team’s ability to coordinate and combine their expertise effectively.
- Interactive Data Visualization: With support for popular data visualization libraries like Matplotlib and Plotly, the SingleStore Notebook enables users to create interactive and informative charts and graphs directly within the notebook environment. This capability is crucial for data scientists who need to communicate their findings visually.
- Ease of Use and Learning Resources: The platform is user-friendly, with templates and documentation to help new users get started quickly. These resources are invaluable for learning the basics of the notebook and for performing complex data analysis tasks.
- Future Enhancements and Integration: The SingleStore team is committed to continuously improving the notebook, with plans to introduce features like import/export, code auto-completion, and a gallery of notebooks for various scenarios. There’s also anticipation for bot capabilities that could facilitate SQL or Python coding in SingleStoreDB.
- Streamlining Python Code Integration: A future goal is to make it easier to prototype Python code in the notebooks and integrate this code as stored procedures in the database, enhancing the overall efficiency and functionality of the system.
SingleStore Notebook is a powerful tool for data professionals, combining the versatility of Jupyter Notebook with specific enhancements for use with SingleStore’s SQL database. Its focus on ease of use, collaboration, and interactive data visualization, along with the promise of future enhancements, makes it a valuable resource in the data science and machine learning communities.
Try different tutorials for free using SingleStore Notebooks feature.
We have very interesting tutorials such as image recognition, image matching, building LLM apps that can See Hear Speak, etc and all you can try for free.
LlamaIndex

LlamaIndex is an advanced orchestration framework designed to amplify the capabilities of LLMs like GPT-4. While LLMs are inherently powerful, having been trained on vast public datasets, they often lack the means to interact with private or domain-specific data. LlamaIndex bridges this gap, offering a structured way to ingest, organize and harness various data sources — including APIs, databases and PDFs.
By indexing this data into formats optimized for LLMs, LlamaIndex facilitates natural language querying, enabling users to seamlessly converse with their private data without the need to retrain the models. This framework is versatile, catering to both novices with a high-level API for quick setup, and experts seeking in-depth customization through lower-level APIs. In essence, LlamaIndex unlocks the full potential of LLMs, making them more accessible and applicable to individualized data needs.
How LlamaIndex works?
LlamaIndex serves as a bridge, connecting the powerful capabilities of LLMs with diverse data sources, thereby unlocking a new realm of applications that can leverage the synergy between custom data and advanced language models. By offering tools for data ingestion, indexing and a natural language query interface, LlamaIndex empowers developers and businesses to build robust, data-augmented applications that significantly enhance decision-making and user engagement.
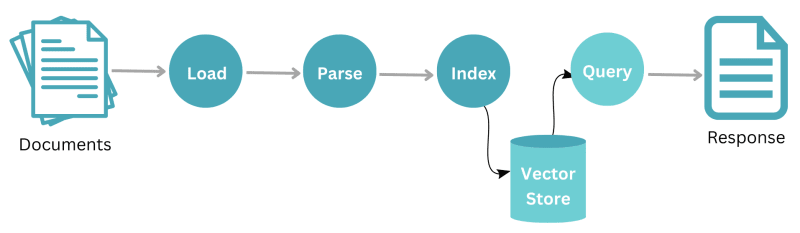
LlamaIndex operates through a systematic workflow that starts with a set of documents. Initially, these documents undergo a load process where they are imported into the system. Post loading, the data is parsed to analyze and structure the content in a comprehensible manner. Once parsed, the information is then indexed for optimal retrieval and storage.
This indexed data is securely stored in a central repository labeled “store”. When a user or system wishes to retrieve specific information from this data store, they can initiate a query. In response to the query, the relevant data is extracted and delivered as a response, which might be a set of relevant documents or specific information drawn from them. The entire process showcases how LlamaIndex efficiently manages and retrieves data, ensuring quick and accurate responses to user queries.
Llama 2

Llama 2 is a state-of-the-art language model developed by Meta. It is the successor to the original LLaMA, offering enhancements in terms of scale, efficiency and performance. Llama 2 models range from 7B to 70B parameters, catering to diverse computing capabilities and applications. Tailored for chatbot integration, Llama 2 shines in dialogue use cases, offering nuanced and coherent responses that push the boundaries of what conversational AI can achieve.
Llama 2 is pre-trained using publicly available online data. This involves exposing the model to a large corpus of text data like books, articles and other sources of written content. The goal of this pre-training is to help the model learn general language patterns and acquire a broad understanding of language structure. It also involves supervised fine-tuning and reinforcement learning from human feedback (RLHF).
One component of the RLHF is rejection sampling, which involves selecting a response from the model and either accepting or rejecting it based on human feedback. Another component of RLHF is proximal policy optimization (PPO) that involves updating the model’s policy directly based on human feedback. Finally, iterative refinement ensures the model reaches the desired level of performance with supervised iterations and corrections.
Hugging Face

Hugging Face is a multifaceted platform that plays a crucial role in the landscape of artificial intelligence, particularly in the field of natural language processing (NLP) and generative AI. It encompasses various elements that work together to empower users to explore, build, and share AI applications.
Here’s a breakdown of its key aspects:
1. Model Hub:
- Hugging Face houses a massive repository of pre-trained models for diverse NLP tasks, including text classification, question answering, translation, and text generation.
- These models are trained on large datasets and can be fine-tuned for specific requirements, making them readily usable for various purposes.
- This eliminates the need for users to train models from scratch, saving time and resources.
2. Datasets:
- Alongside the model library, Hugging Face provides access to a vast collection of datasets for NLP tasks.
- These datasets cover various domains and languages, offering valuable resources for training and fine-tuning models.
- Users can also contribute their own datasets, enriching the platform’s data resources and fostering community collaboration.
3. Model Training & Fine-tuning Tools:
- Hugging Face offers tools and functionalities for training and fine-tuning existing models on specific datasets and tasks.
- This allows users to tailor models to their specific needs, improving their performance and accuracy in targeted applications.
- The platform provides flexible options for training, including local training on personal machines or cloud-based solutions for larger models.
4. Application Building:
- Hugging Face facilitates the development of AI applications by integrating seamlessly with popular programming libraries like TensorFlow and PyTorch.
- This allows developers to build chatbots, content generation tools, and other AI-powered applications utilizing pre-trained models.
- Numerous application templates and tutorials are available to guide users and accelerate the development process.
5. Community & Collaboration:
- Hugging Face boasts a vibrant community of developers, researchers, and AI enthusiasts.
- The platform fosters collaboration through features like model sharing, code repositories, and discussion forums.
- This collaborative environment facilitates knowledge sharing, accelerates innovation, and drives the advancement of NLP and generative AI technologies.
Hugging Face goes beyond simply being a model repository. It serves as a comprehensive platform encompassing models, datasets, tools, and a thriving community, empowering users to explore, build, and share AI applications with ease. This makes it a valuable asset for individuals and organizations looking to leverage the power of AI in their endeavors.
Haystack

Haystack can be classified as an end-to-end framework for building applications powered by various NLP technologies, including but not limited to generative AI. While it doesn’t directly focus on building generative models from scratch, it provides a robust platform for:
1. Retrieval-Augmented Generation (RAG):
Haystack excels at combining retrieval-based and generative approaches for search and content creation. It allows integrating various retrieval techniques, including vector search and traditional keyword search, to retrieve relevant documents for further processing. These documents then serve as input for generative models, resulting in more focused and contextually relevant outputs.
2. Diverse NLP Components:
Haystack offers a comprehensive set of tools and components for various NLP tasks, including document preprocessing, text summarization, question answering, and named entity recognition. This allows for building complex pipelines that combine multiple NLP techniques to achieve specific goals.
3. Flexibility and Open-source:
Haystack is an open-source framework built on top of popular NLP libraries like Transformers and Elasticsearch. This allows for customization and integration with existing tools and workflows, making it adaptable to diverse needs.
4. Scalability and Performance:
Haystack is designed to handle large datasets and workloads efficiently. It integrates with powerful vector databases like Pinecone and Milvus, enabling fast and accurate search and retrieval even with millions of documents.
5. Generative AI Integration:
Haystack seamlessly integrates with popular generative models like GPT-3 and BART. This allows users to leverage the power of these models for tasks like text generation, summarization, and translation within their applications built on Haystack.
While Haystack’s focus isn’t solely on generative AI, it provides a robust foundation for building applications that leverage this technology. Its combined strengths in retrieval, diverse NLP components, flexibility, and scalability make it a valuable framework for developers and researchers to explore the potential of generative AI in various applications.
In conclusion, the landscape of generative AI is rapidly evolving, with frameworks and tools like HuggingFace, LangChain, LlamaIndex, Llama2, Haystack, and SingleStore Notebooks leading the charge. These technologies offer developers a wealth of options for integrating AI into their projects, whether they are working on natural language processing, data analytics, or complex AI applications.
- 登录 发表评论