
category
Introduction
Large Language Models (LLMs) are increasingly utilised across various domains, including question answering over private enterprise documents, where data security and robustness are paramount.
Retrieval-Augmented Generation (RAG) is a prominent framework for building such applications, but ensuring its robustness requires extensive customisation.
This study shares experiences in deploying an LLM application for question answering over private organisational documents, using a system called Tree-RAG (T-RAG) that incorporates entity hierarchies for improved performance.
Evaluations demonstrate the effectiveness of this approach, providing valuable insights for real-world LLM applications.
Data Privacy
Security risks are a primary concern due to the sensitive nature of these documents, making it impractical to use proprietary LLM models over publich APIs, to avoid data leakage risks.
This calls for the use of open-source models that can be deployed on-premise.
Additionally, limited computational resources and smaller training datasets based on available documents present challenges.
Furthermore, ensuring reliable and accurate responses to user queries adds complexity, necessitating extensive customisation and decision-making in deploying robust applications in such environments.
Take-Aways
What interested me in this study is that the researches develop an application that integrates Retrieval-Augmented Generation (RAG) with a fine-tuned open-source Large Language Model (LLM) for generating responses. This model is trained using an instruction dataset derived from the organisation’s documents.
They introduce a novel evaluation metric, termed Correct-Verbose, designed to assess the quality of generated responses. This metric evaluates responses based on their correctness while also considering the inclusion of additional relevant information beyond the scope of the original question.
T-RAG
Below the workflow of Tree-RAG (T-RAG)…
For a given user query, the vector database is searched for the relevant document chunks, the chunk serves as the contextual reference for LLM in-context learning.
If the query mentions any organisational related entities, information regarding the entities is extracted from the entities tree and added to the context. The fine-tuned Llama-2 7B model generates a response from the presented data.
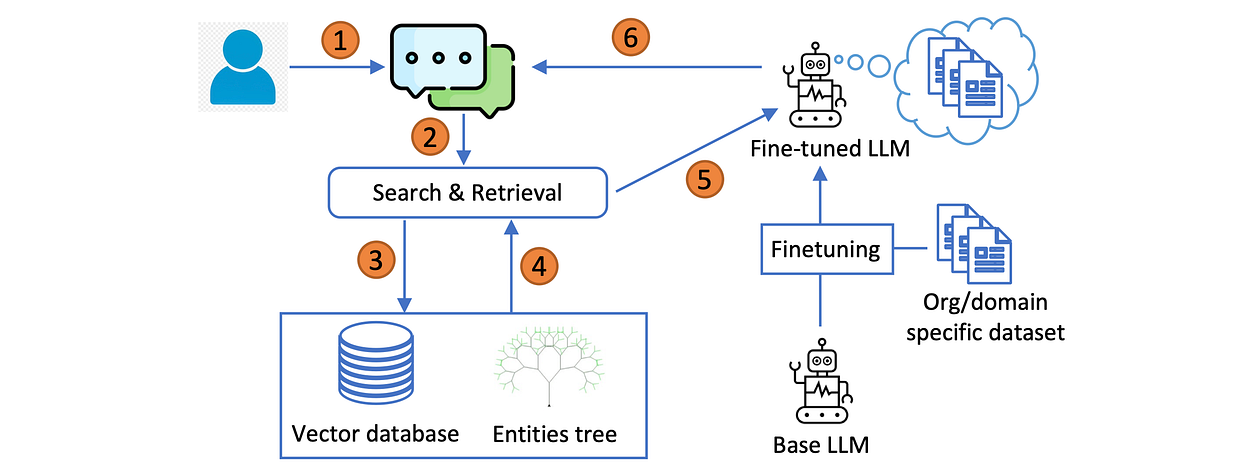
A feature of T-RAG is the inclusion of an entities tree in addition to the vector database for context retrieval.
Entities Tree
One distinguishing aspect of T-RAG is its incorporation of an entities tree alongside the vector database for context retrieval. The entities tree stores details regarding the organization’s entities and their hierarchical arrangement. Each node within this tree represents an entity, with parent nodes indicating their respective group memberships.
During the retrieval process, the framework leverage the entities tree to enhance the context retrieved from the vector database.
The procedure for entity tree search and context generation unfolds as follows:
- Initially, a parser module scans the user query for keywords corresponding to entity names within the organisation.
- Upon identifying one or more matches, details regarding each matched entity are extracted from the tree.
- These details are transformed into textual statements that furnish information about the entity and its position within the organisation’s hierarchy.
- Subsequently, this information is amalgamated with the document chunks retrieved from the vector database to construct the context.
- By adopting this approach, the model gains access to pertinent information about entities and their hierarchical positioning within the organisation when users inquire about them.
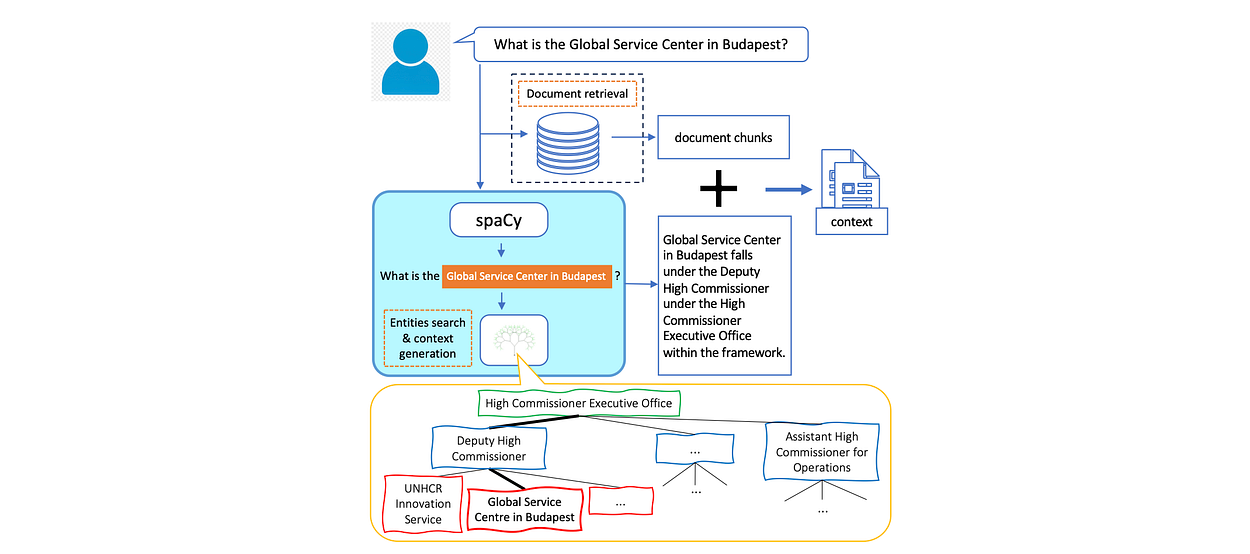
Considering the image above, the retrieval process for context generation involves utilising an illustrative example from an organisational chart to demonstrate how tree search and retrieval are executed.
In addition to fetching contextual documents, a spaCy library is used with custom rules to identify named entities within the organisation.
If the query contains one or more such entities, relevant information regarding the entity’s hierarchical location is extracted from the tree and transformed into textual statements. These statements are then incorporated into the context along with the retrieved documents.
However, if the user’s query does not mention any entities, the tree search is omitted, and only the context from the retrieved documents is utilised.
In Conclusion
I found this study fascinating in the sense that it combines RAG and also fine-tuning. While making use of an open-sourced model hosted on premise to address issues of data-privacy, while simultaneously solving for inference latency, token usage cost and regional and geographic availability.
It is also interesting how entities are used via spaCy framework for entity search and context generation. The fact that this was not just a research piece, but lessons learned based on experiences building an LLM application for real-world use.
- 登录 发表评论