category
编者按:这是兰斯·马丁的一篇客座博客文章。
TL;DR
我们最近开源了一个自动评估工具,用于对LLM问答链进行评分。我们现在发布了一个开源、免费的托管应用程序和API,以扩展可用性。下面我们将讨论一些进一步改进的机会。
上下文
文档问答是一个流行的LLM用例。LangChain可以轻松地将LLM组件(例如,模型和检索器)组装成支持问答的链:输入文档被分割成块并存储在检索器中,在给定用户问题的情况下检索相关块并传递给LLM以合成答案。
问题
质量保证系统的质量可能有很大差异;我们已经看到由于特定的参数设置而产生幻觉和回答质量差的情况。但是,(1)评估答案质量和(2)使用此评估来指导改进的QA链设置(例如,块大小、检索到的文档数)或组件(例如,模型或检索器选择)并不总是显而易见的。
应用程序
自动评估器旨在解决这些限制。它受到了两个领域工作的启发:1)Anthropic最近的工作使用了模型书面评估集,2)OpenAI显示了模型分级评估。该应用程序将这两种想法结合到一个工作空间中,为给定的输入文档自动生成QA测试集,并自动对用户指定的QA链的结果进行评分。Langchain的抽象使得使用用于测试的模块化组件来配置QA变得容易(以下面的颜色显示)。

用法
我们现在发布了一个开源、免费的托管应用程序和API,以扩展可用性。该应用程序可以通过两种方式使用(有关更多详细信息,请参阅自述文件):
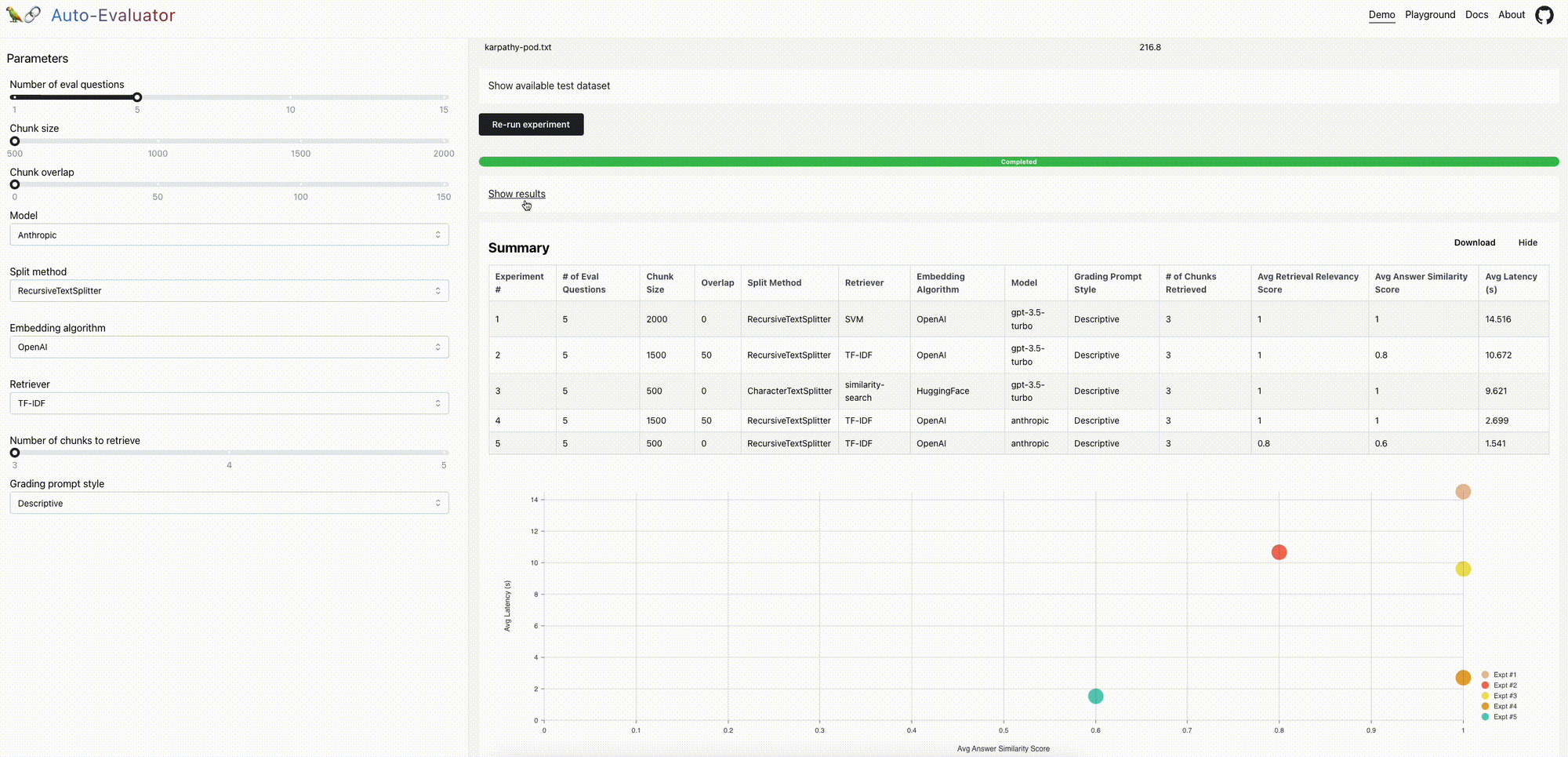
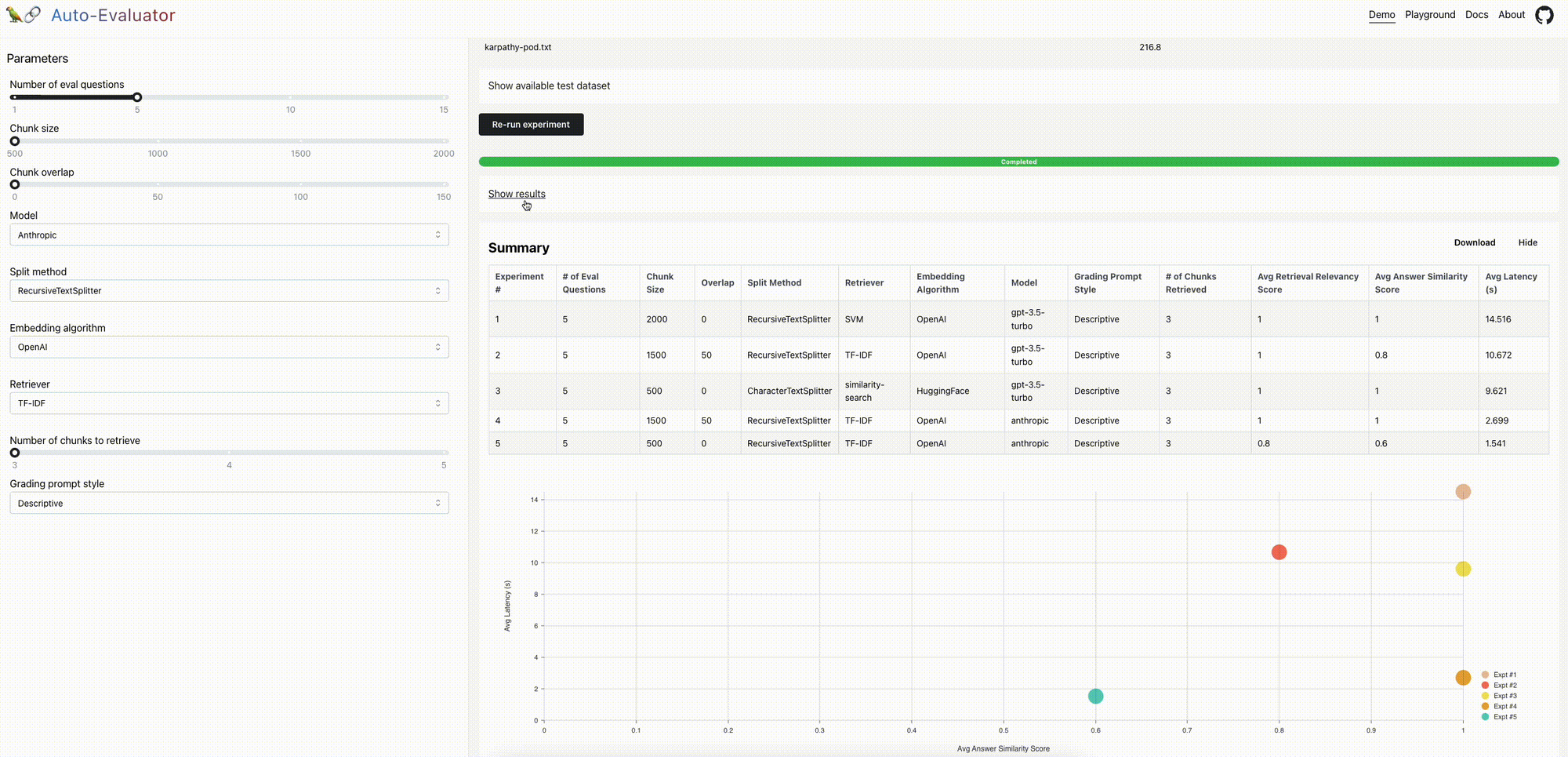
- 演示:我们预装了一份文件(Lex Fridman与Andrej Karpathy的播客的文字记录)和播客中的一组5个问答对。您可以配置QA链并运行实验来评估相对性能。
- 游乐场:受nat.dev游乐场的启发,用户可以输入一个文档来评估各种QA通道。可选地,用户可以包括与文档相关的问答对测试集;请参阅此处和此处的示例。
改进的机会
文件处理
从客户端到后端的文件传输速度较慢。对于2个文件(39MB),传输时间约为40秒:
| PROD | LOCAL | |
|---|---|---|
| OAI embedding | OAI embedding | |
| Stage | Elapsed time | Elapsed time |
| Transfer file | 37 sec | 0 sec |
| Reading file | 5 sec | 1 sec |
| Splitting docs | 3 sec | 3 sec |
| Making LLM | 1 sec | 1 sec |
| Make retriever | 6 sec | 2 sec |
| Success | ✅ | ✅ |
图像会膨胀文件,在从客户端传输之前可能会被剥离:
| PROD | PROD | PROD | PROD | |
|---|---|---|---|---|
| 1.3 MB, 40 pg | 3.5 MB, 42 pg | 7.7MB, 42 pg | 32MB, 54 pg | |
| Stage | Elapsed time | Elapsed time | Elapsed time | Elapsed time |
| Transfer file | 1 sec | 3 sec | 5 sec | 35 sec |
| Reading file | 5 sec | 4 sec | 6 sec | 7 sec |
| Splitting docs | 0 sec | 0 sec | 0 sec | 1 sec |
| Making LLM | 1 sec | 1 sec | 1 sec | 1 sec |
| Make retriever | 3 sec | 3 sec | 3 sec | 4 sec |
| Success | ✅ | ✅ | ✅ | ✅ |
模型书面评估
Anthropic和其他人已经发表了关于模型的书面评估。在这里,为了速度,我们做了一些非常天真的事情:我们随机选择输入上下文,并从中生成QA对。请在我们的博客文章中查看更多详细信息。在这方面有很大的改进机会(例如,根据输入的整体背景提出的问题)。
寻回犬
LangChain检索器抽象包括几种用于文档检索的方法。从向量DB(例如,FAISS、Chroma等)中查找嵌入的k最近邻是一种流行的方法,但也有其他方法。例如,Karpathy最近讨论了使用SVM作为检索器,可以考虑TF-IDF等统计方法。自动评估器使添加和/或测试各种检索器变得容易。我们构建了一个测试集,由Kipply优秀的变压器分类法中的15篇论文组成。这是测试集,当然可以改进:
| QUESTION | ANSWER |
|---|---|
| What corpus of data was GPT-3 trained on? | GPT-3 was trained on a 300B token dataset consisting mostly of filtered Common Crawl, along with some books, webtext and Wikipedia. |
| What is in-context learning? | The broad set of skills and pattern recognition abilities gained during pre-training can be used at inference time to perform novel tasks given only input-output examples without any weight update. It is a an emergent behavior in large language models (LMs). |
| How much better is Galatica than GPT-3 on LaTex equations? | On LaTeX equations, Galatica achieves a score of 68.2% versus the latest GPT-3’s 49.0%. |
| What was the BLOOM model trained on? | BLOOM was trained on the ROOTS corpus, a composite collection of 498 Hugging Face datasets amounting to 1.61 terabytes of text that span 46 natural languages and 13 programming languages. |
| What does the Chinchilla paper argue is important for compute optimal training? | Chinchilla paper finds that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. |
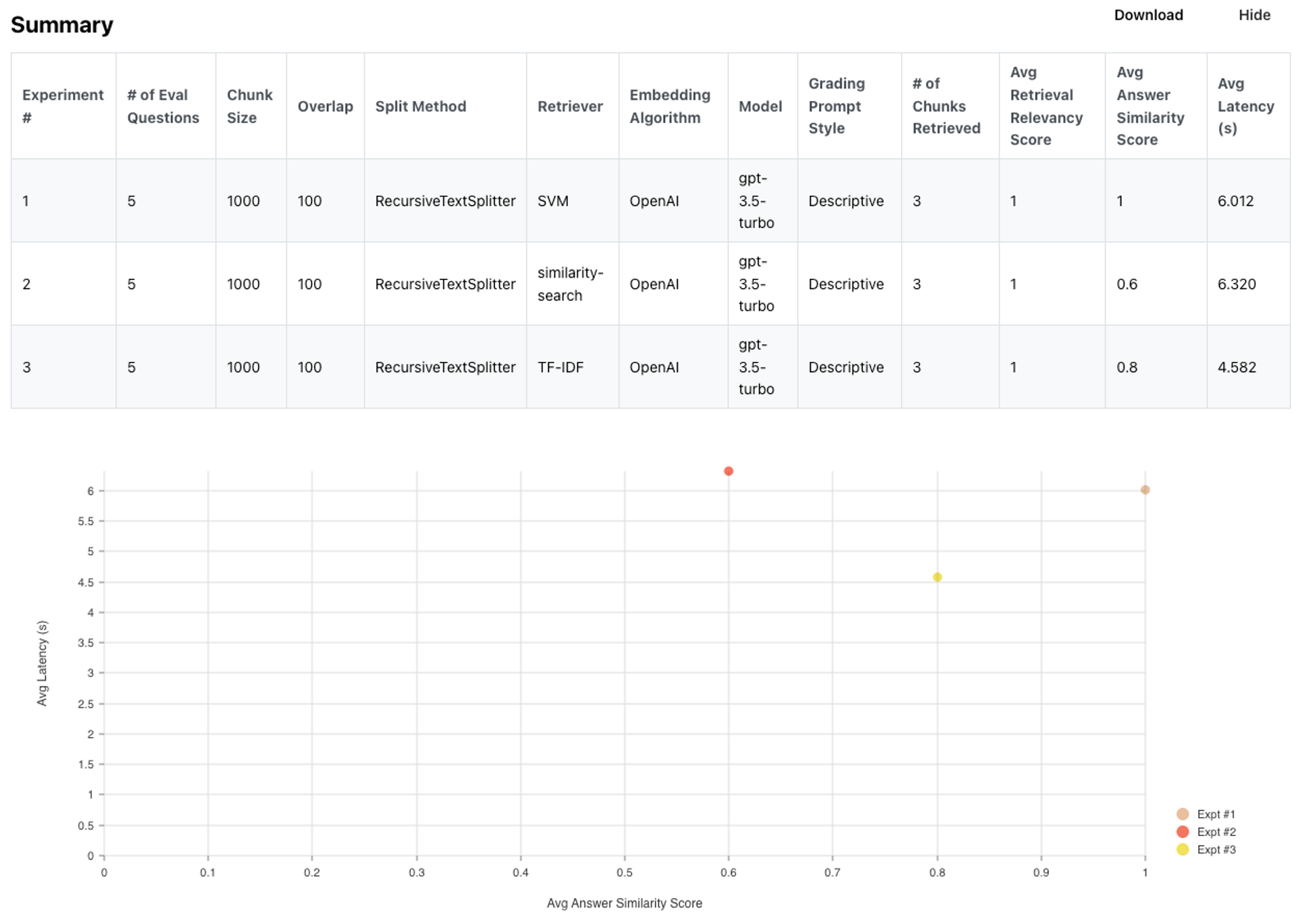
以下是总结结果。你可以在这里看到详细的结果。
简言之,在这种特殊情况下,TF-IDF和SVM的表现都与k-NN相当(事实上,好一点)。当然,这并不总是正确的,但关键是检索有很多选择值得考虑。
模型分级评估
评分提示
中心思想是使用提示对模型生成的答案(和检索到的文档)相对于基本事实答案进行评分。我们测试了几个提示,您可以在这里看到。您可以在此处的每个提示和摘要中看到结果(问题、答案和成绩调整):
| PROMPT | ANSWER SCORE (FRACTION CORRECT) |
|---|---|
| Fast | 5 / 5 |
| Descriptive | 4 / 5 |
| Descriptive with bias | 5 / 5 |
| https://github.com/openai/evals/blob/main/evals/registry/modelgraded/closedqa.yaml | 2 / 5 |
简而言之,答案评分因提示而异(例如,OpenAI评分是最严格的)。未来的工作应侧重于完善模型分级评估的提示。
易变性
该应用程序目前使用GPT-3.5-turbo作为分级器,但与OpenAI的讨论表明GPT4更可取。这里有一个例子:评分者似乎被双重否定所混淆,并为相同的输入答案问题产生了不确定的输出。
| EXPERIMENT | ANSWER | GRADE | JUSTIFICATION |
|---|---|---|---|
| 1 | A building permit is not required for a one-story detached accessory building or structure used as a tool and storage shed, playhouse, or similar use, provided the projected roof area does not exceed 100 square feet. | GRADE: Incorrect | JUSTIFICATION: The student answer is incorrect because it states that a building permit is not required for a structure with a projected roof area of 100 square feet or less, while the true answer states that a permit is required for any structure larger than 100 square feet. |
| 2 | A building permit is not required for one-story detached accessory buildings or structures used as tool and storage sheds, playhouses, and similar uses, provided the projected roof area does not exceed 100 square feet (9.29 m2). | GRADE: Correct | JUSTIFICATION: The student answer accurately states that a building permit is not required for structures under 100 square feet, which is true. |
结论
请随时为开源回购做出贡献或测试免费托管的应用程序。与文件处理、提示(例如,用于QA生成、分级或QA)、模型(例如,从Hugging Face添加开源模型)或检索器相关的贡献是影响最大的几个领域。
- 登录 发表评论