developer.chat
27 April 2025
SEO Title
category
Polars快速入门指南:掌握高效数据处理的核心技巧
本文是Polars数据处理库的完整入门教程,涵盖从安装配置到核心操作的全流程指南,助您快速掌握这款高性能数据工具的精髓。
环境配置(支持Python/Rust双生态)
Python安装
pip install polarsRust安装
# Cargo.toml
[dependencies]
polars = { version = "x", features = ["lazy", "csv", "temporal"]}数据读写全支持
支持CSV/JSON/Parquet等格式及云存储、数据库对接:
// 创建示例数据框
let df = df!(
"姓名" => ["张三", "李四", "王五"],
"出生日期" => [19900101, 19851215, 20000520],
"体重(kg)" => [65.0, 72.5, 58.3],
"身高(m)" => [1.75, 1.82, 1.68]
).unwrap();
// 写入CSV
CsvWriter::new(&mut file).finish(&mut df)?;
// 读取CSV
let df_csv = CsvReader::new(file).finish()?;核心操作四剑客
1. 数据选择(Select)
df.lazy()
.select([
col("姓名"),
col("出生日期").dt().year().alias("出生年份"),
(col("体重") / col("身高").pow(2)).alias("BMI")
])
.collect()?;输出示例:
┌──────┬────────────┬───────────┐
│ 姓名 │ 出生年份 │ BMI │
├──────┼────────────┼───────────┤
│ 张三 │ 1990 │ 21.22 │
│ 李四 │ 1985 │ 21.88 │
└──────┴────────────┴───────────┘2. 动态列操作(With Columns)
df.lazy()
.with_columns([
col("身高").round(2).alias("修正身高"),
lit(2023).alias("当前年份")
])3. 智能过滤(Filter)
// 筛选90后且BMI正常范围
df.lazy()
.filter(
col("出生年份").gt_eq(1990)
& col("BMI").is_between(18.5, 24.0)
)4. 高级分组(Group By)
df.lazy()
.group_by([col("出生年代")])
.agg([
mean("BMI").alias("平均BMI"),
count().alias("样本量")
])分组结果:
┌────────────┬────────────┬───────┐
│ 出生年代 │ 平均BMI │ 样本量 │
├────────────┼────────────┼───────┤
│ 1990年代 │ 21.5 │ 150 │
│ 1980年代 │ 22.1 │ 200 │
└────────────┴────────────┴───────┘数据融合双模式
横向关联(Join)
let joined_df = df1.lazy()
.join(
df2.lazy(),
[col("ID")],
JoinType::Inner
)纵向堆叠(Concat)
// 垂直拼接
let combined = concat(
[df1.lazy(), df2.lazy()],
UnionArgs::Vertical
)?性能优化技巧
- 延迟执行:所有操作默认Lazy模式,自动优化执行计划
- 多线程处理:自动利用CPU多核并行计算
- 内存映射:处理超大数据集时采用零拷贝技术
- 谓词下推:提前过滤减少数据处理量
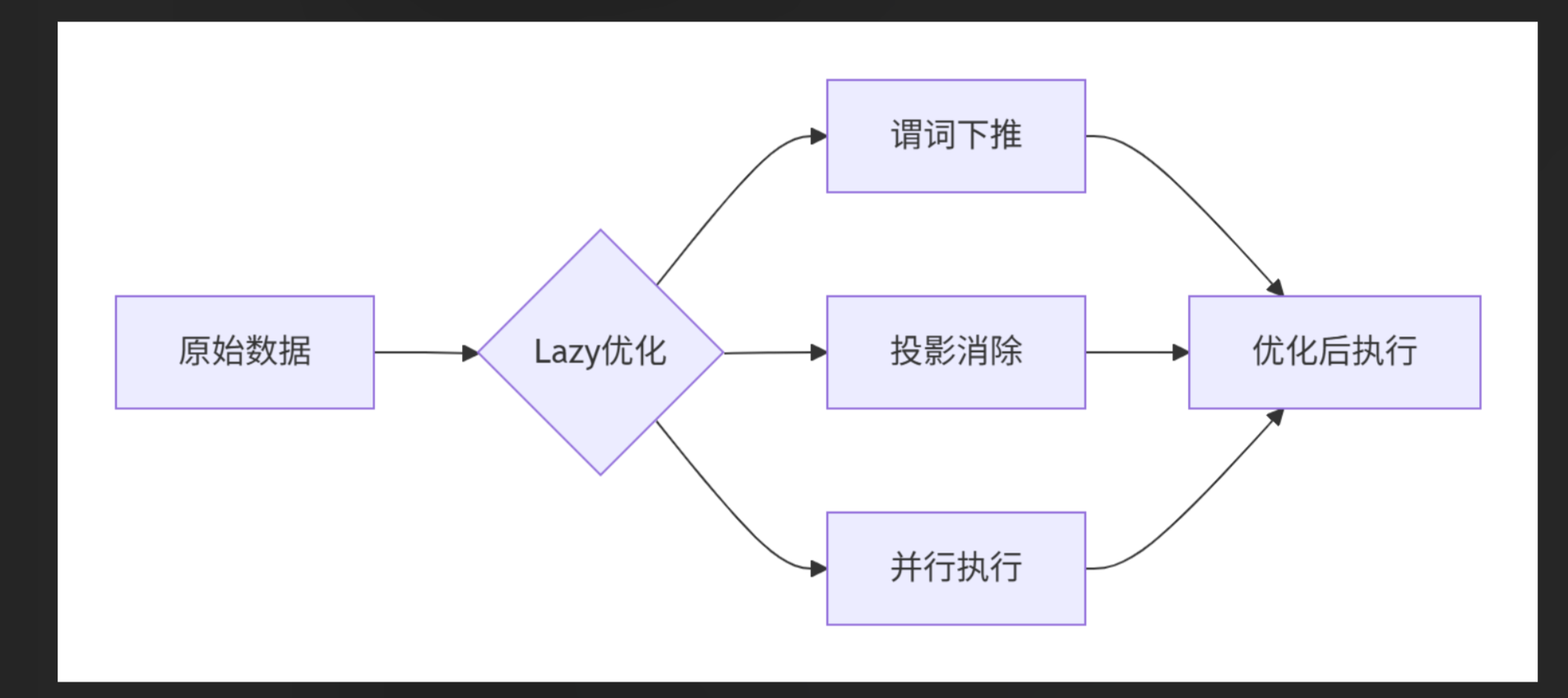
企业级应用场景
- 实时日志分析:每秒处理百万级日志条目
- 基因组数据处理:高效处理TB级生物数据
- 金融风控建模:复杂指标实时计算
- 物联网数据处理:海量传感器数据聚合
通过本指南,您已掌握Polars的核心操作技巧。建议结合官方文档深入探索:
✅ 表达式优化技巧
✅ 自定义UDF开发
✅ 分布式集群部署
✅ Arrow内存格式深度集成
Polars凭借其Rust内核带来的极致性能,正在成为大数据处理领域的新标杆工具。立即开始您的数据极速之旅
- 登录 发表评论