TL;DR:我们正在调整我们的抽象,以便在LangChain中使用除LangChain VectorDB对象之外的其他检索方法。这样做的目的是(1)允许在LangChain中更容易地使用在其他地方构建的检索器,(2)鼓励对替代检索方法(如混合搜索)进行更多实验。这是向后兼容的,所以所有现有的链都应该像以前一样继续工作。然而,我们建议尽快从VectorDB链更新到新的Retrieval链,因为这些链将是未来最受支持的链。
介绍
自从ChatGPT问世以来,人们一直在为自己的数据构建个性化的ChatGPT。我们甚至为此写了一篇教程,然后在几个月前举办了一场关于这方面的比赛。对此的渴望和需求凸显了ChatGPT的一个重要局限性——它不知道你的数据,如果知道的话,大多数人会发现它更有用。那么,你是如何构建一个了解你的数据的聊天机器人的呢?
实现这一点的主要方法是通过一个通常被称为“检索增强生成”的过程。在这个过程中,系统不只是将用户问题直接传递给语言模型,而是“检索”任何可能与回答问题相关的文档,然后将这些文档(以及原始问题)传递到语言模型进行“生成”步骤。
包括我们LangChain在内的大多数人进行检索的主要方式是使用语义搜索。在这个过程中,为所有文档计算一个数字向量(嵌入),然后将这些向量存储在向量数据库(一个为存储和查询向量而优化的数据库)中。然后传入的查询也被向量化,并且检索到的文档是嵌入空间中最接近查询的文档。我们在这里不打算过多详细介绍,但这里有一个关于这个主题的更深入的教程,下面是一个很好地总结了这一点的图表。
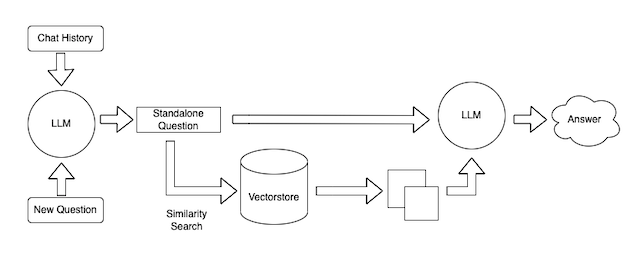
Diagram of typical retrieval step
问题
这个过程运行得很好,我们构建的许多组件和抽象(嵌入、向量库)都旨在促进这个过程。
但我们注意到了两个问题。
- 首先:在如何执行这个检索步骤方面有很多不同的变化。人们希望做语义搜索之外的事情。具体而言:
- 我们支持两种不同的查询方法:一种只优化相似性,另一种优化最大边际相关性。
- 用户通常希望在进行语义搜索之前指定元数据过滤器来过滤结果
- 其他类型的索引,如图,已经引起了用户的兴趣
- 第二:我们还意识到,人们可能会在LangChain之外构建一个检索器——例如,OpenAI发布了他们的ChatGPT检索插件。我们希望让人们尽可能容易地使用他们在LangChain中创建的任何寻回器。
我们意识到我们犯了一个错误——通过以VectorDBQA为中心进行抽象,我们限制了链的使用,使它们很难使用(1)对于想要尝试其他检索方法的用户,(2)对于在LangChain生态系统之外创建检索器的用户。
解决方案
那么我们是如何解决的呢?
在我们最新发布的Python和TypeScript中,我们已经:
- 引入了猎犬(Retriever)的概念。检索器应该公开一个具有以下签名的get_relevant_documents方法:def get_relevant_documents(self, query: str) -> List[Document]。这是我们对寻回犬的唯一假设。请参阅下面关于此界面的更多信息。
- 将我们所有使用VectorDB的链更改为现在使用Retriever。VectorDBQA现在是RetrievalQA,ChatVectorDBChain现在是ConversationalRetrievalChain,等等。请注意,向前看,我们有意使用Conversational前缀来指示链正在使用内存,而Chat前缀则表示链正在使用聊天模型。
- 添加了非LangChain检索器的第一个实例-ChatGPT检索插件。这是OpenAI昨天开源的一个模块,旨在帮助公司公开检索端点以连接到ChatGPT。注意:就所有意图和目的而言,ChatGPT检索插件的内部工作方式与我们的VectorStores非常相似,但我们仍然非常兴奋能够将其集成为一种突出现有新灵活性的方式。
在Retriever接口上进行扩展:
- 我们有目的地只需要一个方法(get_relevant_documents),以便尽可能宽松。我们(还)不需要任何统一的方法来构建这些检索器。
- 我们有目的地将query:str作为唯一的参数。对于所有其他参数(包括元数据过滤),这应该作为参数存储在检索器本身上。这是因为我们预计检索器通常嵌套在链中,并且我们不希望在其他参数周围有铅垂。
这一切的最终目标是让替代检索器(除了LangChain VectorStore)更容易在链和代理中使用,并鼓励替代检索方法的创新。
问答
Q: 索引和检索器有什么区别?
A: 索引是一种支持高效搜索的数据结构,检索器是使用索引来查找和返回相关文档以响应用户查询的组件。索引是检索器执行其功能所依赖的关键组件。
Q: 如果我以前在VectorDBQA链(或其他VectorDB类型的链)中使用VectorStore,那么我现在在RetrievalQA链中使用什么?
A: 您可以使用VectorStoreRetriever,您可以通过执行vectorstore.as_retriever()从现有的vectorstore创建它
Q: VectorDBQA链(或其他VectorDB类型的链)是否仍然存在?
A: 是的,尽管我们将不再专注于此。预计未来的任何开发都将在RetrievalQA链上完成。
Q: 我能为library贡献一种新的检索方法吗?
A: 是的!我们正是为此目的启动了一个新的langchain/retrievers模块
Q: 现实世界中有哪些这样的例子?
A: 主要的一个是比你的文件更好的问答。然而,如果开始摄取并检索以前的信息,这可以被认为是人工智能更好的长期记忆。
- 登录 发表评论