category
推荐系统将始终保持相关性——用户希望看到个性化的内容,最好的目录(就我们的iFunny应用程序而言,是流行的表情包和笑话)。我们的团队正在测试数十个关于智能提要如何改善用户体验的假设。本文将告诉您我们是如何实现协作模型之上的第二级模型的:我们遇到了什么困难,以及它们是如何影响指标的。
通常,矩阵分解,如隐式分解。ALS用于帮助改善饲料。在这种方法中,对于每个用户和每个对象,我们都会得到嵌入,而嵌入最接近用户嵌入的内容(在余弦度量中)最终会出现在最受欢迎的推荐中。
该方法工作迅速,但没有考虑所有信息(例如,在矩阵分解中添加用户的性别和年龄将是一项挑战)。
两级推荐系统试图在不放弃“永恒经典”的情况下使用更复杂的算法
实施两层推荐系统
我们需要从各种算法中“组装”出一个顶级解决方案。我们拥有:
- 用户与内容交互的用户项矩阵
- 表格用户特征(性别、年龄等)
- 表格项目特征(标签、模因文本等)
我们可以将用户和项目特征输入到增强算法中——让我们以LigitGBM为例,它在处理表格数据方面表现出色(甚至比神经网络更好)。如果我们将[user_id,item_id]对视为分类基数特征(Users*Items)并应用一个热编码,我们也可以将矩阵发送到那里。但这里出现了两个问题:
- 如果用户之前没有与该项目进行过交互,则此功能将为空
- 基数太高,boosting无法处理那么多拆分
让我们回想一下,我们有ALS(交替最小二乘)矩阵分解,所以我们计算用户嵌入与每个内容嵌入的标量积。我们有效地引入了高基数特征[user_id,item_id],并解决了上述两个问题。现在,标量积可以用作增强和考虑“表格”功能的强大项目功能。事实证明,我们有效地利用了所有可用的数据。
你如何在生产中应用这些机制?我们想向用户展示目录中数十万个模因中排名前100的模因。虽然这种增强很酷,但推理需要很长时间——数十万条内容无法通过。这就是为什么我们分两个阶段提出建议:
- 从数十万个单元中,我们选择“候选”——嵌入接近用户嵌入的前100个单元。
- 我们在助推器的帮助下对100个元素进行排名。
这种方法相对快速且经过验证——这就是所有顶级系统的工作原理。例如,阅读Milvus创建者的文章——该公司为候选人选择制作了一款产品。如果有很多数据,可以有几个级别的候选人选择。
但是,当然,并非没有问题。我们将在下面描述它们。
模型验证
选择合适的验证方案(即将数据集拆分为训练和验证的方法)对于ML管道至关重要。理想情况下,系统应该是证明指标的变化与模型运行期间在线指标的变化相一致(即,验证指标的改进=在线指标的保证改进)。
我们考虑了以下方案:
- 随机分割——对90%的数据集进行训练,使用剩余的10%进行验证
- 时间分割——我们从数据集中截断了几个小时
- 本文有一个有趣的想法:将交互分解为会话,并验证会话中的最后一个内容
由于应用程序的特殊性,每小时都会出现新内容,因此当我们需要推荐少量交互的内容时,我们必须不断解决“冷启动”的问题。这就是为什么第二种方式看起来是最可取的,我们选择了它。此外,这个方案在生产中使用了(我们在grafana中记录了这个指标),这使得比较离线和在线指标变得更加容易。
比较矩阵分解和混合推荐的难点之一是不同的目标。例如,在第一层,我们试图预测交互本身,其中矩阵因式分解损失试图以最佳方式近似用户项矩阵。相比之下,第二级通常使用排名损失函数。
排名损失并没有显示出质量的显著提高,因此我们决定使用LogLoss。在第二个层面上,我们解决了分类问题,并学会了确定与之产生积极互动的内容:点赞、分享和转发。
为了更容易、更精确地比较输出,我们在streamlit上对推荐内容进行了可视化:
特征工程
切换到两级模型的主要动机是用新功能丰富模型的可能性。除了第一级的矩阵分解外,我们还可以区分另外两种类型的元素:
- “表格”——不随时间变化的常数:用户的性别和年龄、内容类型(图片/视频)等;
- “统计”-当您与服务交互时会发生变化的各种计数器:会话的平均长度、应用程序的访问次数、不同内容类别中的点赞次数等。
通过“表格”功能,一切都很明显:在推理过程中,模型从在线存储库(在我们的例子中是Mongo)获取内容属性,而在离线训练时,我们使用传输到Clickhouse的相同数据的副本。
使用窗口函数和其他方法,统计特征最初是在Clickhouse中计算的。结果很快发现,产品解决方案被“调整”为从Kafka中提取数据,而原型应该使用Clickhouse的数据。不同的来源是潜在的问题,因此决定在MVP中使用Kafka作为数据准备的数据源。
最初,这项任务应该使用许多不同的统计特征。尽管如此,为了加快MVP在生产中的部署,我们决定停止使用最简单的MVP,例如:
- 对于一个模因,我们用smile_rate来计算——微笑数量与内容浏览总数的比率。
- 对于用户,我们计算img_smile_rate(用于图片)和video_smile_rate(用于视频),以了解用户更喜欢哪种类型的内容。
对于未来,我们已经与机器学习工程团队达成一致,开发一项服务,从中我们可以获得推理和训练的功能。将有灵活的管道来添加新功能并将这些功能交付给模型。
在讨论功能的最后,我会注意到一个重要点:在部署到生产环境之前,与机器学习工程师讨论转换是至关重要的。例如,设备类型(iPhone、iPad、Android)是OneHot编码的一个明确特征,如果你在训练和推理过程中使用不同的编码,模型将无法正常工作。为了降低风险,我们在Confluence中创建了一个页面,在那里我们描述了输入数据转换并检查了几个文本用户的建议(在Jupyter中训练的模型的排名不应与生产中的模型排名不同)。
Catboost与LightGBM
当功能准备就绪时,选择一个特定的增强实现是必要的。它们有很多,但现在最受欢迎的是Catboost和LightGBM。每个框架在准备功能时都有具体的细节,所以我建议做一点lifehack——在研究了文档后,看看实际的代码:
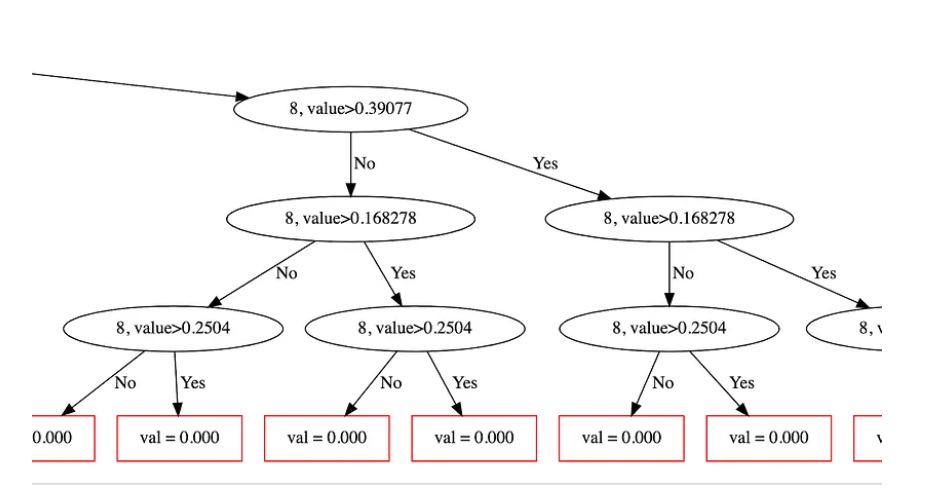
我们拒绝了CatBoost,因为树中的分割对我们的数据产生了奇怪的影响(见图片中的最后一层——分割在不同的决策树节点中达到了相同的值)。
因此,LightGBM立即启动。我们决定使用它。唯一令人困惑的是预测分数的分布。在第一级的矩阵分解中,我们看到了一个从0到1的“重尾”分布。
LightGBM的得分分布方差要低得多:
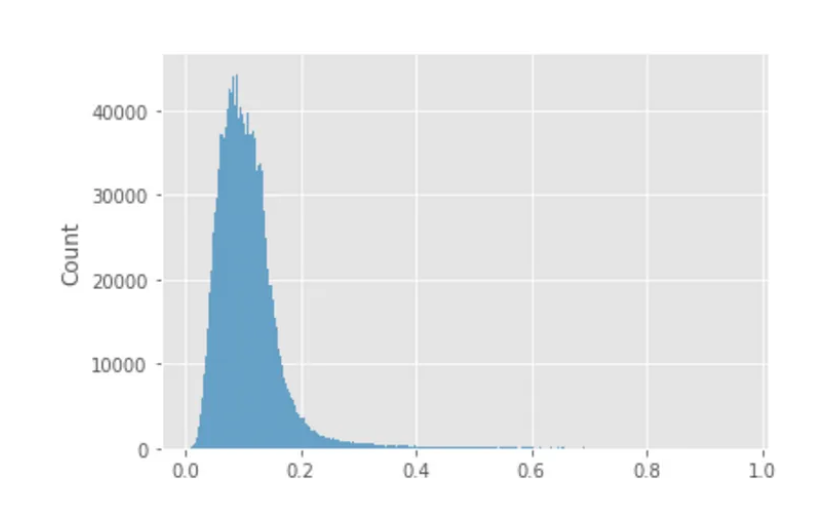
图表显示,该模型很少预测接近1的值,这很奇怪。然而,LightGBM的排名指标更好,所以我们决定忽略评分分布中的奇怪之处(顺便说一句,如果你的实践中有这样的情况,请在评论中写下来)。
如何避免数据泄露
为了了解我们正在谈论的泄漏,让我们回顾一下第一级和第二级连接在我们的混合推荐系统中是如何工作的:
- 学习如何挑选得分最高的热门内容
- 将内容得分和附加功能输入到二级模型输入中
重要的一点是:如果你先在整个数据集上训练第一层,然后训练第二层,你会发现数据泄漏。在第二层,矩阵分解的内容得分将考虑目标信息,因此使用以下规则:
- 我们将数据集分为因子化训练集(90%训练)和增强训练集(10%训练)
- 在因式分解训练中训练第一级(矩阵因式分解)
- 对boosting_train_set进行矩阵分解评分预测
- 通过添加表格和统计特征,对boosting_Train_set进行训练增强
在这里,我们遇到了一些困难:我们需要对生产中的100%交互进行培训。否则,我们将丢失有关用户偏好的重要信息。这里有两种选择:
- 分批训练(首先在工厂化训练中,然后在增压训练中单独训练一批)
- 首先训练两级模型的整个周期,然后分别训练第一级进行生产
这两种方法都有缺点:首先,我们不确定模型权重是否会收敛到正确的值;在第二种情况下,我们在培训上花费了两倍的硬件资源。我们选择了第二种方法来尽量减少对现有模型训练管道的干扰。
实验结果
试运行的结果相当令人沮丧。我们没有看到测试组的参与度指标有任何增长(图表显示了几天内smile_rate的数据):
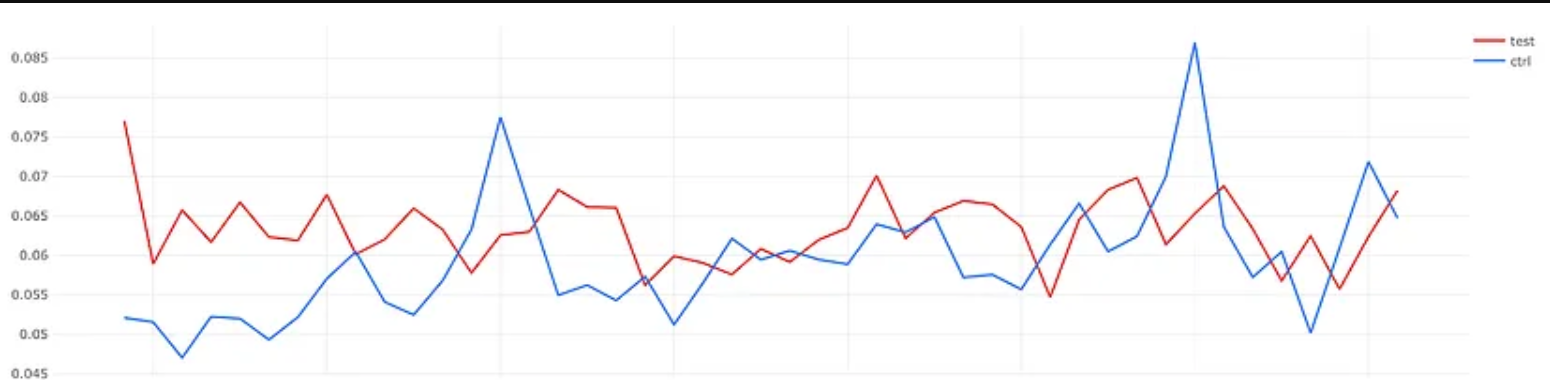
我们没有看到实验中指标的增加。为什么会这样?
梯度提升的主要优点是,您可以使用许多其他功能进行排名。由于架构限制,我们添加了一些组件,因此我们同意回滚实验并进行一些改进,以便快速添加和测试模型中的新功能。
下一步去哪里
现在我们正在开发推荐系统,朝着两个方向发展:改进系统的架构和排名算法。
建筑改进:
- 创建功能存储服务,以确保在推理中使用与训练中使用的功能相同的功能
- 将LightGBM模型引入一个单独的微服务中(我们有想法尝试ONNX)
改进算法:
- 添加更多特征——统计和表格(例如,来自卷积网络的图片嵌入,我们称之为内容嵌入)
- 训练其他目标(例如,允许排名损失)
- 为候选人组合多个来源(除了通过矩阵分解评分进行选择外,您还可以通过受欢迎程度收集内容,使用其他分解模型,如ALS,或通过内容嵌入进行相似性分析)
- 更改离线验证方案(也许可以找到最佳模型参数)。
我们的下一系列将详细描述这些改进及其对业务指标的影响。
- 登录 发表评论