
ChatGPT席卷全球。数以百万计的人在使用它。但尽管它对通用知识很有帮助,但它只知道自己接受过哪些培训的信息,即2021年之前普遍可用的互联网数据。它不知道你的私人数据,也不知道最近的数据来源。
如果真的这样做了,那不是很有用吗?
这篇博客文章是关于如何在特定的数据语料库上设置自己的ChatGPT版本的教程。有一个附带的GitHub 代码库,其中有本文中引用的相关代码。具体来说,这涉及到文本数据。有关如何使用自然语言层与其他数据源交互,请参阅以下教程:
- SQL数据库
- API(API)
高级演练
在高级别上,有两个组件可以在您自己的数据上设置ChatGPT:(1)数据的接收,(2)数据上的聊天机器人。在这里以高水平走过每个步骤:
数据摄入
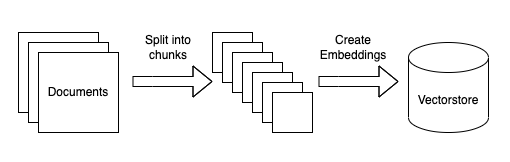
Diagram of ingestion process
这可以通过几个子步骤来打破。所有这些步骤都是高度模块化的,作为本教程的一部分,我们将介绍如何替换步骤。步骤如下:
- 将数据源加载到文本:这涉及到将数据从任意源加载到可以在下游使用的文本中。这是一个我们希望社区能够提供帮助的地方!
- 分块文本:这包括将加载的文本分块成更小的块。这是必要的,因为语言模型通常对它们可以处理的文本量有限制,所以创建尽可能小的文本块是必要的。
- 嵌入文本:这包括为每个文本块创建一个数字嵌入。这是必要的,因为我们只想为给定的问题选择最相关的文本块,并且我们将通过在嵌入空间中找到最相似的块来做到这一点。
- 将嵌入加载到向量库:这涉及到将嵌入和文档放入向量库。Vectorstores帮助我们快速有效地找到嵌入空间中最相似的块。
数据查询
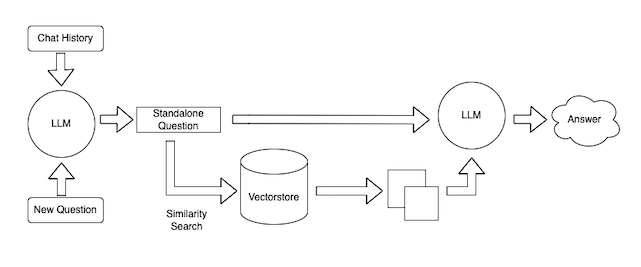
Diagram of query process
这也可以分为几个步骤。同样,这些步骤是高度模块化的,并且主要依赖于可以替代的提示。步骤如下:
将聊天历史记录和一个新问题合并为一个单独的问题。这是必要的,因为我们希望能够提出后续问题(一个重要的用户体验考虑因素)。
- 查找相关文档。使用摄取过程中创建的嵌入和向量库,我们可以查找相关文档以获得答案
- 生成响应。给定独立的问题和相关文档,我们可以使用语言模型生成响应
- 我们还将简要介绍这个聊天机器人的部署,尽管不要花太多时间(未来的帖子!)
数据摄入
本节将详细介绍获取数据所需的步骤。
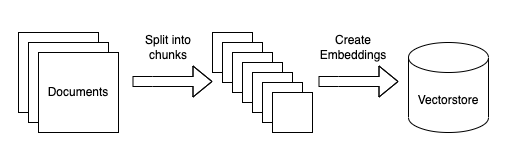
Diagram of ingestion process
加载数据
首先,我们需要将数据加载到标准格式中。同样,因为本教程关注的是文本数据,所以常见的格式将是LangChain Document对象。这个对象非常简单,包括(1)文本本身,(2)与该文本相关的任何元数据(它来自哪里,等等)。
因为有太多潜在的地方可以加载数据,所以我们希望这一领域将受到社区的大力推动。至少,我们希望得到很多关于如何从源加载数据的示例笔记本。理想情况下,我们将把加载逻辑添加到核心库中。请参阅此处查看现有的示例笔记本,并参阅此处查看底层代码。如果你想投稿,可以直接打开PR,或者用你的作品片段打开GitHub问题。
下面的行包含负责加载相关文档的代码行。如果您想更改文档加载的逻辑,这是您应该更改的代码行。
loader = UnstructuredFileLoader("state_of_the_union.txt")
raw_documents = loader.load()
拆分文本
除了加载文本之外,我们还需要确保将其分成小块。这是必要的,以确保我们只将最小、最相关的文本片段传递给语言模型。为了分割文本,我们需要初始化一个文本分割器,然后在原始文档上调用它。
下面的行对此负责。如果您想更改文本的拆分方式,您应该更改这些行
text_splitter = RecursiveCharacterTextSplitter() documents = text_splitter.split_documents(raw_documents)
创建嵌入并存储在vectorstore中
接下来,既然我们有了小块文本,我们需要为每一段文本创建嵌入,并将它们存储在向量库中。这样做是为了让我们可以使用嵌入来只找到要发送到语言模型的最相关的文本片段。
这是通过以下几行完成的。在这里,我们使用OpenAI的嵌入和FAISS向量库。如果我们想更改所使用的嵌入或所使用的向量库,这就是我们要更改它们的地方。
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
最后,我们保存创建的向量库,以便以后使用。这样,我们只需要运行一次这个摄取脚本。
with open("vectorstore.pkl", "wb") as f:
pickle.dump(vectorstore, f)
这就是摄取脚本的全部内容!根据您的偏好修改后,您可以运行“python intake_data.py”来运行脚本。这应该会生成一个“vectorstore.pkl”文件。
查询数据
因此,现在我们已经获取了数据,我们现在可以在聊天机器人界面中使用它。为了做到这一点,我们将使用ChatVectorDBChain。为了定制这个链条,我们可以改变一些事情。
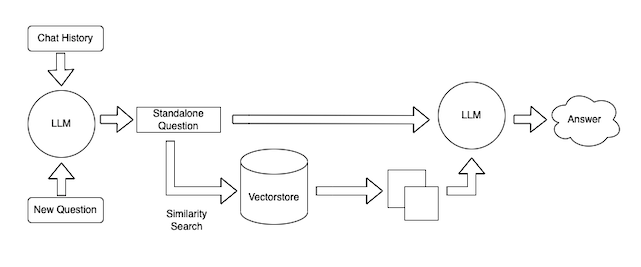
Diagram of ChatVectorDBChain
精简问题提示
我们可以控制的第一件事是接收聊天历史记录和新问题并生成独立问题的提示。这是必要的,因为这个独立的问题随后被用来查找相关文档。
这是一个偷偷摸摸的重要步骤。如果你只是使用新问题来查找相关文档,你的聊天机器人将无法很好地处理后续问题(因为在之前的交流中可能有查找相关文档所需的信息)。如果您将整个聊天历史记录与新问题一起嵌入以查找相关文档,则可能会提取与对话不再相关的文档(如果新问题根本不相关)。因此,将聊天历史记录和一个新问题浓缩为一个独立问题的步骤非常重要。
此提示是query_data.py文件中的CONCEE_QUESTION_prompt。
问答提示
你可以拉动的另一个杠杆是接收文档的提示和回答问题的独立问题。这可以自定义为您的聊天机器人提供特定的对话风格。
此提示是query_data.py文件中的QA_prompt
注意:在使用GitHub回购时,必须更改此提示。其中的当前提示指定他们应该只回答有关联合地址状态的问题,这适用于伪示例,但可能不适合您的用例。
语言模型
最后一个杠杆是你用什么语言模型来为你的聊天机器人提供动力。在我们的例子中,我们使用了OpenAI LLM,但它可以很容易地替换为LangChain支持的其他语言模型,或者您甚至可以编写自己的包装器。
把它们放在一起
在进行了所有必要的自定义并运行了python ingest_data.py之后,您如何与这个聊天机器人进行交互?
我们已经公开了一个非常简单的接口,您可以通过它来访问。您只需运行python cli_app.py就可以访问它,这将在终端中打开一种提问和获取答案的方式。试试看!、

我们还有一个通过Gradio部署此应用程序的示例!你可以通过运行python app.py来实现这一点。这也可以很容易地部署到Hugging Face空间——请参阅这里的示例空间。

- 登录 发表评论