消除真实世界私人数据识别的实用方法
随着互联网服务的普及,人们对互联网隐私的渴望不断增长。近年来,诸如GDPR等不同的法律开始发挥作用,这些法律规范了服务收集私人信息的方式。这引起了每家公司对隐私方面的关注,并增加了对处理和匿名私人数据的投资。
我在微软商业软件工程(CSE)团队的工作是与微软最具战略意义的客户合作。我们共同开发人工智能、大规模数据、物联网等领域的新工作负载。在与这些客户接触的同时,我们意识到,PII(个人身份信息)问题是许多希望在本地或云中扩展其解决方案集的公司反复出现的话题和障碍。
因此,我们决定为任何希望解决数据隐私问题的人创建Presidio,这是一项免费的生产准备开源服务。
Presidio允许任何用户在结构化和非结构化数据上创建标准和透明的匿名PII实体流程。为此,它公开了一组预定义的PII识别器(用于名称、信用卡号和电话号码等常见实体),以及用新逻辑扩展它的工具,以识别更具体的PII实体。在这篇博客文章中,我们将重点讨论如何利用自然语言处理来识别不同类型的私人实体。
PII检测过程
Presidio利用一组识别器,每个识别器都能够检测一种或多种语言的一个或多个PII实体。该过程如图1所示,通常由8个不同的步骤组成:
- 从用户处获取匿名化请求
- 将请求传递给Presidio Analyzer以识别PII实体
- 提取NLP特征(引理、命名实体、关键词、词性等),供各种识别器使用
- 获取所有PII识别器(预定义的+来自识别器存储服务的自定义)
- 运行所有识别器
- 汇总结果
- 传递给Presidio匿名者进行身份验证
- 将取消标识的文本返回给呼叫者
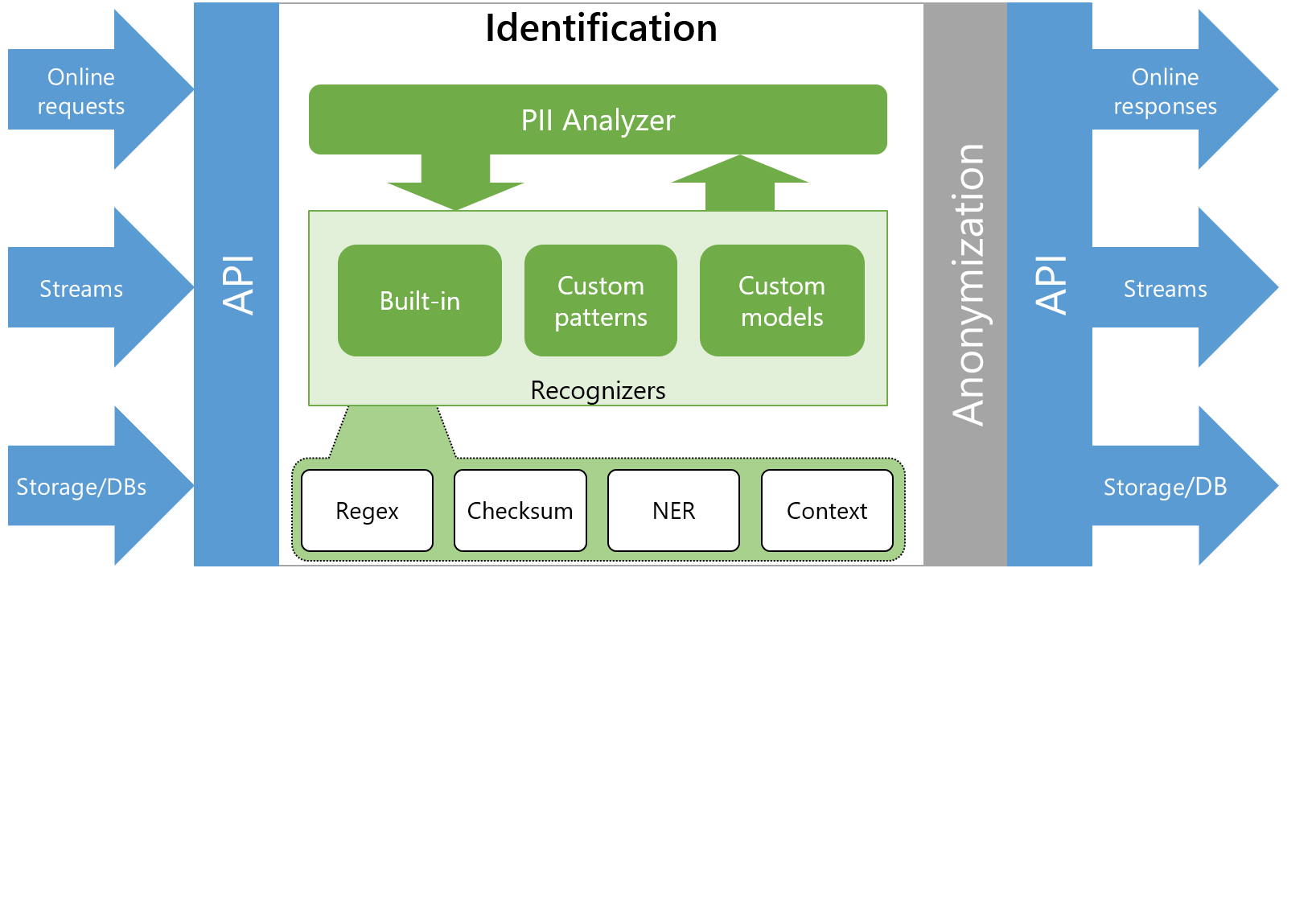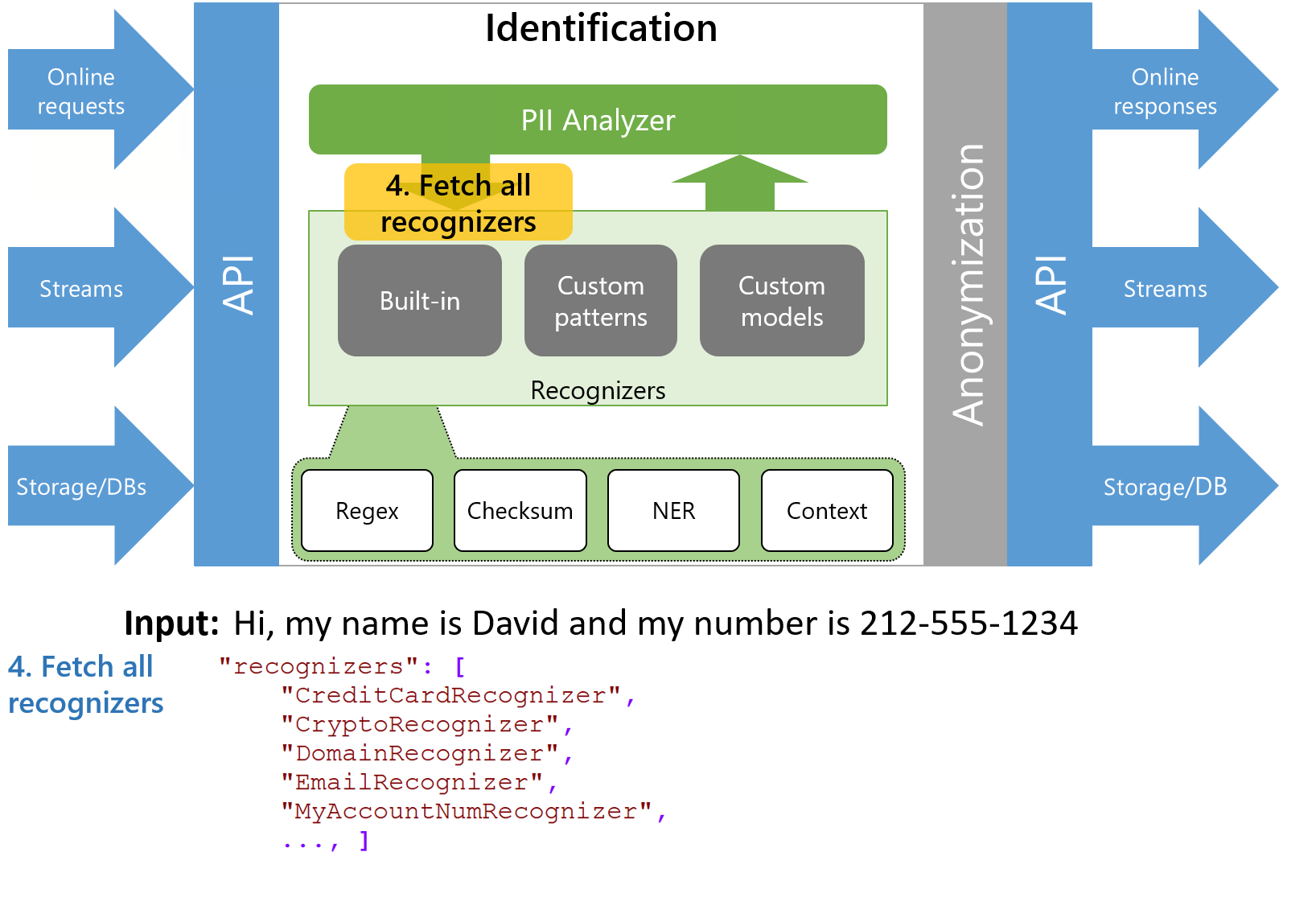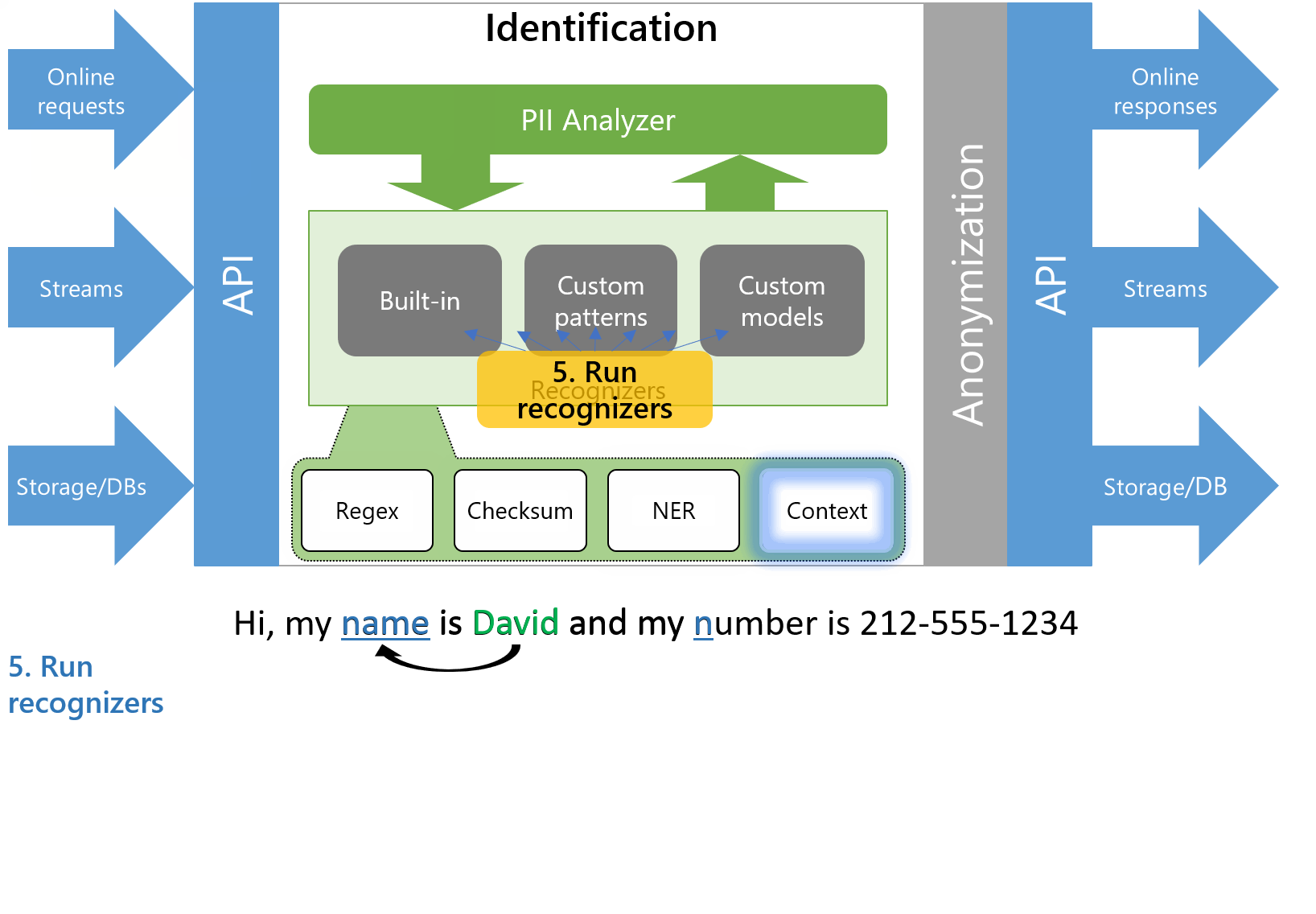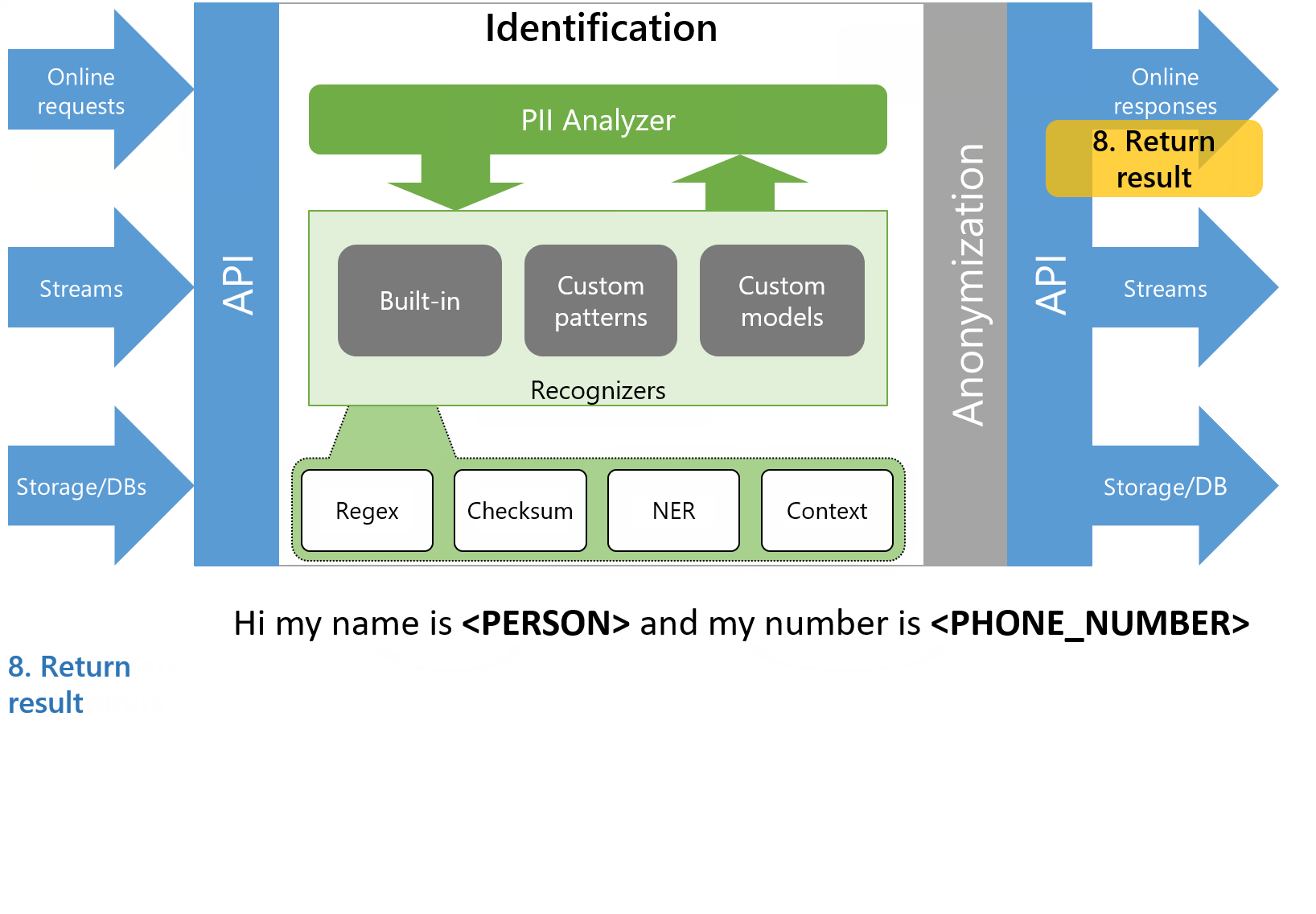
Figure 1 — Animation of the identification process in Presidio
图2中的以下动画说明了一个特定示例中的相同过程。请注意,当我们将上下文从“电话号码”更改为“池卡号”时,电话号码识别器的可信度会降低。这是Presidio演示的屏幕截图。看看吧。

Figure 2 — Example input and output
用于数据匿名化的NLP
PII识别器需要检测自由文本中不同类型的实体。对于这样的任务,人们想到了不同的NLP方法:
- 对于共享模式的实体,我们可以利用正则表达式、验证(例如校验和)和周围单词的上下文。例如,该逻辑可以用于检测信用卡号码或电话号码。
- 对于有限的选项列表,我们可以使用黑名单。它可以是静态黑名单(例如所有标题:先生、女士、小姐、博士、教授…),也可以是动态黑名单(即连接到数据库并查询所有可能的选项)。
- 对于可以使用特定逻辑识别的实体,我们可以编写基于规则的识别器。
- 对于需要自然语言理解输入的实体,我们可以训练机器学习模型,特别是命名实体识别(NER),或者使用预先训练的模型。
在下一节中,我们将重点介绍我们围绕提高人名、地点和组织的命名实体识别率所做的工作。
人名、地点和组织的NER
为了提高我们对这三个实体的检测率,我们对不同的模型进行了实验。以下部分介绍了使用的数据集、评估的不同模型和结果。运行此过程的代码可以在我们的GitHub repo上找到,以供研究。
数据集集合
虽然有一些标记的数据集可用,但我们希望增加名称、组织和位置的覆盖范围。因此,我们从一个标记的数据集(例如,OntoNotes或CoNLL-2003)开始,并对其进行处理以提取模板。这些例子后来被用来生成新的句子,与原始数据集相比,这些句子具有更广泛的实体值(名称、组织和位置)。
例如,从“谢谢你,乔治!”这句话中,乔治被手动标记为人,我们提取了以下模板:“谢谢你[人]!”。图3提供了一个附加示例:

Figure 3 — Data augmentation example
我们使用了一个伪造的PII数据集和多个伪造的PI生成器来对实体进行采样并创建新的句子。这些句子在生成过程中被自动标记,因此训练新的NER模型很容易适用。
然而,这个过程需要我们对数据集进行一些预处理,并为不同的问题提出创造性的解决方案。举几个例子:
- 如何看待国家与国籍?在许多情况下,“地点”实体指的是一个民族(或民族男子或民族妇女)。例如,在“萨尔瓦多[LOC]拳击手赢得了世界冠军”这句话中,我们不能用“埃塞俄比亚”代替“萨尔瓦多”,因为这会使这句话不正确。因此,我们为国家、民族、民族男人和民族女人创造了新的中间实体。
- 应该如何处理性别问题?有些句子最初是关于男性或女性的,但在数据生成过程中,我们可能会用异性的名字代替一个名字。
- 现实生活中的知识是否重要?如果原话描述的是两个国家之间的冲突,我们是否应该用任意的国名取代这些国家?
- 数据集中的一些人名是一个机构或组织的名称,如“艾伦人工智能研究所”或“特朗普政府”。在这种情况下,我们是否应该用一个任意的名字来取代“特朗普”?
从8000个独特的模板中,我们提取了80000个不同的标记句子。我们还获得了比前一个更干净的数据集,因为在这个过程中处理了许多未标记的实体。新数据集被拆分为训练/测试/验证集,来自同一模板的样本没有出现在多个集中。此外,我们将10%的样本设为小写,因为这通常表示部署模型时可能遇到的小写文本的比例。据我们所知,这是迄今为止最大的PII数据集。
模型
对不同的建模方法进行了评估。具体来说,我们研究了条件随机场、基于spaCy的模型和基于Flair的模型。
spaCy:
spaCy是一个用于标记化、词性标记、实体提取、文本分类等的生产级NLP库。它包含一个卷积神经网络模型,被认为是最快的深度学习NLP模型。虽然其他模型在公共数据集上具有更高的准确性,但它们可能需要更长的训练和推理时间。spaCy还提供了快速标记化和引理化,用于Presidio中的上下文分析模块。我们评估了spaCy的不同风格:首先,我们查看了预训练的spaCy模型(2.1.0和2.2.0)的结果,然后,我们查看微调预训练的spaCy模型,最后,在利用预训练的单词嵌入(FastText)的同时从头开始训练spaCy模型。
Flair:
Flair是一个深度学习NLP工具包,在公共数据集上取得了有希望的结果。它建立在PyTorch之上,同时具有特殊的嵌入技术(称为Flair嵌入)和预测模型。此外,它提供了与其他嵌入模型(如BERT、ELMo)的简单集成,以及来自不同模型和源的嵌入的堆叠。我们评估了两种不同的基于Flair的模型:一种是带有BERT嵌入的Flair模型,另一种是具有Flair嵌入和GloVe嵌入堆叠的Flair模式。
条件随机场(CRF):
CRF是一类用于序列标记的方法。这些具有鉴别力的图形模型学习预测之间的相关性,自然适合命名实体识别任务。在引入递归和卷积神经网络之前,CRF在公共数据集上的NER任务上实现了最先进的性能。它们在训练和预测方面比基于神经网络的模型快得多,并且提供了相对可解释的结果。我们使用sklearn-crfsuite-Python包,使用L-BGFS优化仅评估了香草CRF模型。
最后,以下是我们试验的模型:
- 使用默认的预训练模型进行评估:
- spaCy 2.1.0
- spaCy 2.2.0(对小写实体有更好的支持)
- 从头开始训练:
- 条件随机场
- 使用预训练的嵌入进行训练:
- 带有FastText嵌入的spaCy
- 嵌入BERT的Flair
- 带有GloVe和Flair嵌入的Flair
- 对现有的训练模型进行微调:
- spaCy版本2.2.0
度量标准
我们关注PII/no-PII二元决策的F2(回忆比准确性更重要)。我们还研究了特定的类F2和计算性能。最后,可解释性是一个需要考虑的额外因素。
结果
如图4所示,所有模型都取得了不错的结果,但基于Flair的模型更出色。

从这些结果中得出的一些见解:
- 基于Flair的模型比基于spaCy的模型取得了更高的结果,后者在所有实体上取得了比CRF更高的成果。
- 我们可以看到,spaCy 2.2.0提供了比预期的2.1.0更好的结果,但数量不多。
- spaCy和CRF模型在组织实体方面遇到了困难,组织实体经常与人名混淆。Flair模型在组织上获得了更高的结果,这可能暗示过度拟合为组织生成的假PII实体。
- 训练spaCy模型或对其进行微调都无法提高模型的F2分数。这可能是由于训练集的性质,该训练集源自spaCy最初训练的同一数据集(OntoNotes)。其他数据来源可能会从这些模型的微调或训练中受益。
计算性能
尽管Flair模型获得了更高的F2分数,但它们的训练和预测也要慢得多。表1显示了使用所评估的各种方法的近似训练和推理时间。分析是在一台GPU机器上进行的[1]。

[1] Azure上的NC6实例:6 vCPU,56GiB内存,一半NVIDIA特斯拉K80,GPU内存12GiB
结论
在这项工作中,我们评估了各种模型,以便在Presidio中获得更好的检测率。我们考虑了检测率和计算性能之间的权衡,这在许多用例中是至关重要的。对于我们评估的数据集,我们发现没有实际的理由来取代我们在Presidio中使用的当前spaCy模型。然而,可以将数据扩充框架和评估的不同模型应用于新数据,并针对更特定领域的数据集定制Presidio。我们还看到,通过使用CRF模型而不是spaCy,我们可以潜在地改善Presidio的运行时间。如果性能不是问题,例如对于离线作业,我们应该考虑使用基于Flair的方法,可能使用Flair嵌入+GloVe,以提高Presidio中的检测率。
Presidio是完全开源的,免费提供给任何希望解决数据隐私问题的人。我们也欢迎贡献者、拉取请求或任何形式的反馈。单击此处开始。
有关详细信息
其他参考文献
- 登录 发表评论