category
了解使用ChatGPT/LLM创建自己的问答引擎所需的体系结构和数据要求。
 你能用自己的数据训练一个私人聊天GPT进行问答吗?(绿色输出,来自OpenAI:)是的,可以用自己的数据训练私人聊天GPT进行问答。您可以使用各种工具和技术来做到这一点,例如使用预先训练的模型并使用自己的数据对其进行微调,或者从头开始训练模型。
你能用自己的数据训练一个私人聊天GPT进行问答吗?(绿色输出,来自OpenAI:)是的,可以用自己的数据训练私人聊天GPT进行问答。您可以使用各种工具和技术来做到这一点,例如使用预先训练的模型并使用自己的数据对其进行微调,或者从头开始训练模型。
事情会这么简单吗?(回复由text-davinci-003生成)(图片由作者提供)
随着像ChatGPT和GPT-4这样的大型语言模型(LLM)的兴起,许多人都在问是否有可能用他们的公司数据训练私人ChatGPT。但这可行吗?这样的语言模型能提供这些功能吗?
在本文中,我将讨论创建利用您自己的数据的“您的私有ChatGPT”所需的体系结构和数据需求。我们将探讨这项技术的优势,以及如何克服其目前的局限性。
免责声明:本文概述了架构概念,这些概念不是Azure特有的,但由于我是微软的解决方案架构师,因此使用Azure服务进行了说明。
1.使用自己的数据微调LLM的缺点
人们通常将微调(训练)称为在预先训练的语言模型上添加自己的数据的解决方案。然而,正如在最近的GPT-4公告中提到的那样,这有幻觉风险等缺点。除此之外,GPT-4只接受了截至2021年9月的数据训练。
微调LLM时的常见缺点;
- 事实的正确性和可追溯性,答案从何而来
- 访问控制,无法将某些文档限制为特定用户或组
- 成本、新文档需要对模型和模型宿主进行再培训
这将使使用微调来进行问答(QA)变得极其困难,几乎不可能。我们如何才能克服这些限制,并仍然从这些LLM中受益?

A brain (represents knowledge) and AI (computer) separated from each other — (Image by DALL·E 2)
2.将你的知识与你的语言模型分开
为了确保用户得到准确的答案,我们需要将我们的语言模型与知识库分离。这使我们能够利用对语言模型的语义理解,同时为用户提供最相关的信息。所有这些都是实时发生的,不需要进行模型训练。
在运行时将所有文档馈送到模型似乎是个好主意,但由于可以同时处理的字符限制(以令牌为单位),这是不可行的。例如,GPT-3最多支持4K个令牌,GPT-4最多支持8K或32K个令牌。由于定价是每1000个代币,因此使用更少的代币也有助于节省成本。
为此采取的方法如下:
- 用户提出问题
- 应用程序找到(最有可能)包含答案的最相关文本
- 向LLM发送包含相关文档文本的简洁提示
- 用户将收到答案或“未找到答案”响应
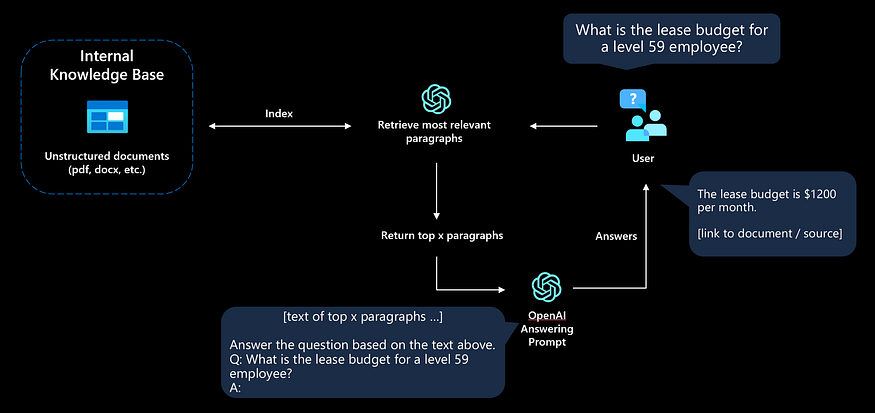
这种方法通常被称为模型的基础( grounding the model)。该应用程序将为语言模型提供额外的上下文,以便能够根据相关资源回答问题。
现在您已经了解了开始构建这样一个场景所需的高级体系结构,现在是时候深入研究技术细节了。
3.检索最相关的数据
上下文是关键。为了确保语言模型具有正确的信息,我们需要建立一个知识库,用于通过语义搜索找到最相关的文档。这将使我们能够为语言模型提供正确的上下文,使其能够生成正确的答案。
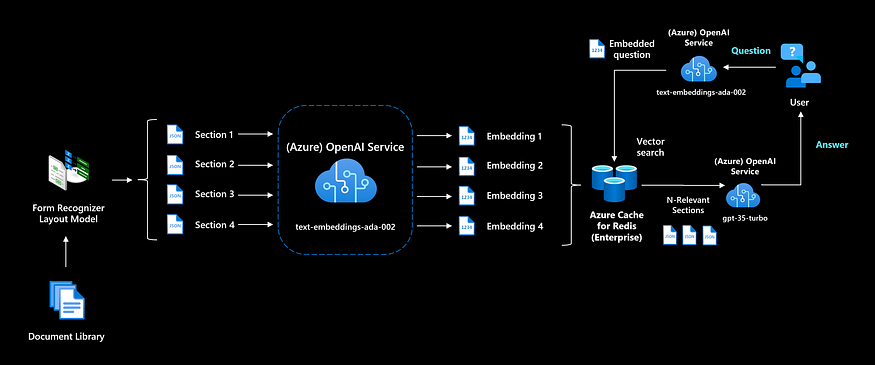
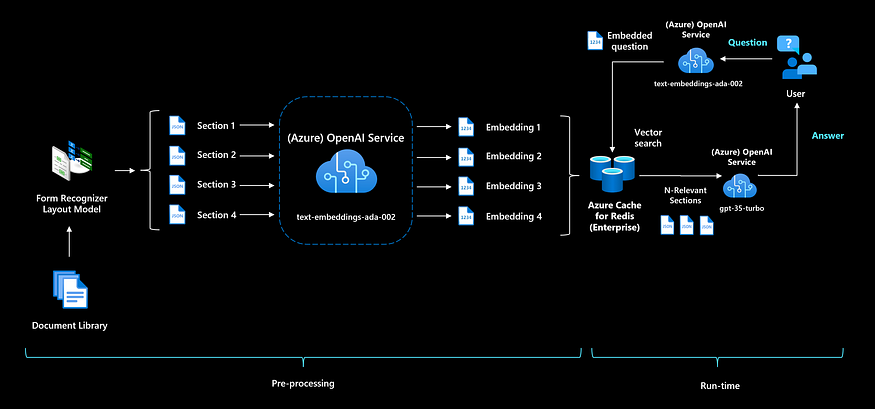
3.1分块和拆分数据
由于应答提示有令牌限制,我们需要确保将文档切成更小的块。根据区块的大小,您还可以共享多个相关部分,并在多个文档上生成答案。
我们可以从简单地按页面分割文档开始,也可以使用按设置的标记长度进行分割的文本分割器。当我们的文档具有更易于访问的格式时,是时候创建一个搜索索引了,该索引可以通过向它提供用户问题来查询。
在这些块的旁边,应该向索引中添加额外的元数据。存储原始来源和页码,以便将答案链接到原始文档。存储可用于访问控制和筛选的其他元数据。
选项1:使用搜索产品
构建语义搜索索引的最简单方法是利用现有的“搜索即服务”平台。例如,在Azure上,您可以使用认知搜索,它提供了一个托管的文档接收管道和语义排名,利用了Bing背后的语言模型。
选项2:使用嵌入来构建自己的语义搜索
嵌入是浮点数字的矢量(列表)。两个向量之间的距离测量它们的相关性。小距离表示高相关性,大距离表示低相关性。[1]
如果你想利用最新的语义模型并对搜索索引有更多的控制权,你可以使用OpenAI的文本嵌入模型。对于您的所有部分,您都需要预先计算嵌入并存储它们。
在Azure上,您可以将这些嵌入存储在托管向量数据库中,如Azure Cache for Redis(RediSearch),或存储在开源向量数据库中(如Weaviate或Pinecone)。在应用程序运行期间,您将首先将用户问题转化为嵌入,这样我们就可以将问题嵌入的余弦相似性与我们之前生成的文档嵌入进行比较。
(关于嵌入的深入研究可以在《走向数据科学》上找到)
3.2提高不同分块策略的相关性
为了能够找到最相关的信息,了解您的数据和潜在的用户查询是很重要的。你需要什么样的数据来回答这个问题?这将决定如何最好地分割数据。
可能提高相关性的常见模式有:
- 使用滑动窗口;按页面或按令牌进行分块可能会产生丢失上下文的不良影响。使用滑动窗口在你的区块中有重叠的内容,以增加在区块中拥有最相关信息的机会。
- 提供更多上下文;一个非常结构化的文档,其中的章节嵌套了多个层次(例如第1.3.3.7节),可以受益于额外的上下文,如章节和章节标题。您可以解析这些部分,并将此上下文添加到每个块中。
- 摘要,创建包含较大文档节摘要的块。这将使我们能够捕捉到最重要的文本,并将其整合在一个区块中。
4.写一个简洁的提示以避免产生幻觉(hallucination)
设计提示就是如何对模型进行“编程”,通常是通过提供一些说明或一些示例。[2]
您的提示是ChatGPT实现的重要组成部分,可以防止不必要的响应。如今,人们称即时工程为一项新技能,每周都有越来越多的样本被分享。
在提示中,您需要明确的是,模型应该简洁,并且只使用所提供上下文中的数据。当它不能回答问题时,它应该提供一个预定义的“不回答”回答。输出应包括原始文件的脚注(引文),以允许用户通过查看来源来验证其事实准确性。
此类提示的一个示例:
"You are an intelligent assistant helping Contoso Inc employees with their healthcare plan questions and employee handbook questions. " + \
"Use 'you' to refer to the individual asking the questions even if they ask with 'I'. " + \
"Answer the following question using only the data provided in the sources below. " + \
"For tabular information return it as an html table. Do not return markdown format. " + \
"Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. " + \
"If you cannot answer using the sources below, say you don't know. " + \
"""
###
Question: 'What is the deductible for the employee plan for a visit to Overlake in Bellevue?'
Sources:
info1.txt: deductibles depend on whether you are in-network or out-of-network. In-network deductibles are $500 for employee and $1000 for family. Out-of-network deductibles are $1000 for employee and $2000 for family.
info2.pdf: Overlake is in-network for the employee plan.
info3.pdf: Overlake is the name of the area that includes a park and ride near Bellevue.
info4.pdf: In-network institutions include Overlake, Swedish and others in the region
Answer:
In-network deductibles are $500 for employee and $1000 for family [info1.txt] and Overlake is in-network for the employee plan [info2.pdf][info4.pdf].
###
Question: '{q}'?
Sources:
{retrieved}
Answer:
"""
来源:azure search openai演示中使用的提示(麻省理工学院许可证)
一次性学习用于增强反应;我们提供了一个应该如何处理用户问题的示例,并为源提供了唯一的标识符和由多个源的文本组成的示例答案。在运行时,{q}将由用户问题填充,{retried}将由知识库中的相关部分填充,以获得最终提示。
如果你想要更重复、更确定的响应,不要忘记通过参数设置低温。温度升高会导致更多意想不到或创造性的反应。
此提示最终用于通过(Azure)OpenAI API生成响应。如果您使用gpt-35-turbo模型(ChatGPT),您可以依次传递对话历史记录,以便能够提出澄清问题或使用其他推理任务(例如摘要)。GitHub上的dair ai/prompt engineering Guide是了解更多关于即时工程的好资源。
https://youtu.be/E5g20qmeKpg
The video describes the high-level architecture of Bing Chat and Microsoft 365 Copilot, who use a similar architecture.
5.接下来的步骤
在本文中,我确实讨论了构建实现所需的体系结构和设计模式,而没有深入研究代码的细节。这些模式现在很常用,下面的项目和笔记本可以作为灵感,帮助您开始构建这样的解决方案。
- ChatGPT Retrieval Plugin,让ChatGPT访问最新信息。目前,这只支持公共ChatGPT,但希望将来能够在ChatGPT-API(OpenAI+Azure)中添加插件。
- LangChain,结合LLM和其他计算或知识来源的流行库
- Azure Cognitive Search + OpenAI accelerator,通过您自己的数据获得类似ChatGPT的体验,准备部署
- OpenAI Cookbook,如何在Jupyter笔记本中利用OpenAI嵌入进行问答的示例(不需要基础设施)
- Semantic Kernel,,将传统编程语言与LLM混合在一起的新库(提示模板、链接和规划功能)
最终,您可以考虑通过LangChain或Semantic Kernel等工具将“您自己的ChatGPT”链接到更多的系统和功能来扩展它。可能性是无限的。
结论
总之,仅仅依靠语言模型来生成事实文本是一个错误。微调模型也无济于事,因为它不会给模型提供任何新的知识,也不会为您提供验证其响应的方法。要在LLM之上构建问答引擎,请将您的知识库与大型语言模型分离,并仅根据提供的上下文生成答案。
If you enjoyed this article, feel free to connect with me on LinkedIn, GitHub or Twitter.
References
- [1] Embeddings — OpenAI API. March 2023, https://platform.openai.com/docs/guides/embeddings
- [2] Introduction— OpenAI API. March 2023, https://platform.openai.com/docs/introduction/prompts
- [3] Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., Zhang, Y. “Sparks of Artificial General Intelligence: Early experiments with GPT-4” (2023), arXiv:2303.12712
- [4] Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., Scialom, T. “Toolformer: Language Models Can Teach Themselves to Use Tools” (2023), arXiv:2302.04761
- [5] Mialon, G., Dessì, R., Lomeli, M., Nalmpantis, C., Pasunuru, R., Raileanu, R., Rozière, B., Schick, T., Dwivedi-Yu, J., Celikyilmaz, A., Grave, E., LeCun, Y., Scialom, T. “Augmented Language Models: a Survey” (2023),
- arXiv:2302.07842
- 登录 发表评论