category
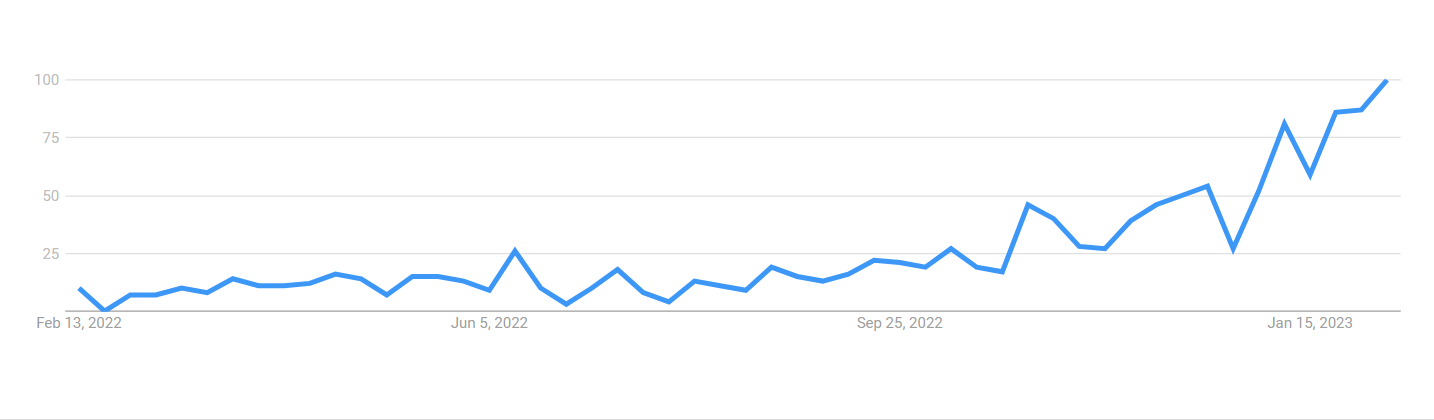
Figure 1: Search volumes for “large language models”
近几个月来,大型语言模型(LLM)引起了很大的轰动(见图1)。这种需求导致了利用语言模型的网站和解决方案的不断开发。ChatGPT在2023年1月创下了用户群增长最快的记录,证明了语言模型将继续存在。谷歌对ChatGPT的回应Bard于2023年2月推出,这也表明了这一点。
语言模型也为企业带来了新的可能性,因为它们可以:
- 自动化流程
- 节省时间和金钱
- 驱动器个性化
- 提高任务的准确性
然而,大型语言模型是计算机科学的一个新发展。正因为如此,商业领袖们可能对这种模式并不了解。我们写这篇文章是为了用大型语言模型告诉好奇的商业领袖:
- 释义
- 示例
- 使用案例
- 训练
- 好处
- 挑战
什么是大型语言模型?
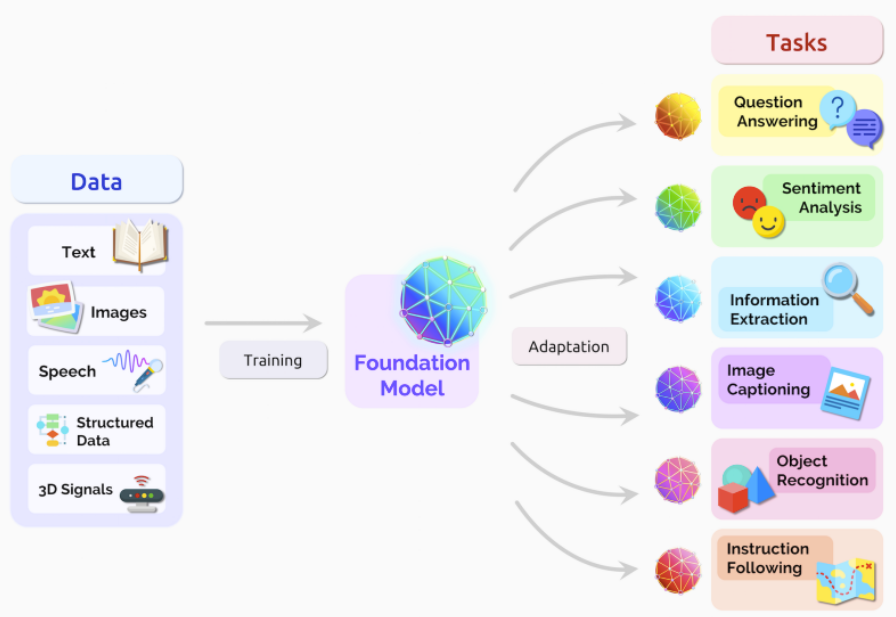
Figure 2: Foundational model, Source: ArXiv
大型语言模型(LLM)是在自然语言处理(NLP)和自然语言生成(NLG)任务中利用深度学习的基础模型。为了帮助他们学习语言的复杂性和联系,大型语言模型是根据大量数据进行预训练的。使用以下技术:
- 微调(Fine-tuning)
- 情境学习 (In-context learning)
- 零次/一次/几次射击学习 (Zero-/one-/few-shot learning)
这些模型可以适用于下游(特定)任务(见图2)。
LLM本质上是一种基于Transformer的神经网络,谷歌工程师在2017年的一篇题为《注意力是你所需要的一切》的文章中介绍了它。1该模型的目标是预测下一个可能出现的文本。一个模型的复杂程度和性能可以通过它有多少参数来判断。模型的参数是在生成输出时考虑的因素数量
大型语言模型示例
有许多开源语言模型可以在内部部署或在私有云中部署,这意味着快速的业务采用和强大的网络安全。此类别中的一些大型语言模型包括:
- BLOOM
- NeMO LLM
- XLM-RoBERTa
- XLNet
- Cohere
- GLM-130B
语言模型的用例是什么?
大型语言模型可以应用于各种用例和行业,包括医疗保健、零售、科技等。以下是所有行业中存在的用例:
- 文本摘要
- 文本生成
- 情绪分析
- 内容创建
- 聊天机器人、虚拟助理和对话式人工智能
- 命名实体识别
- 语音识别与合成
- 图像标注
- 文本到语音合成
- 拼写更正
- 机器翻译
- 推荐系统
- 欺诈检测
- 代码生成
如何训练大型语言模型
大型语言模型是深度学习神经网络,是人工智能和机器学习的一个子集。大型语言模型首先经过预训练,以便学习基本的语言任务和功能。预训练是一个需要大量计算能力和尖端硬件的步骤。
Figure 2: Pre-training vs. fine-tuning

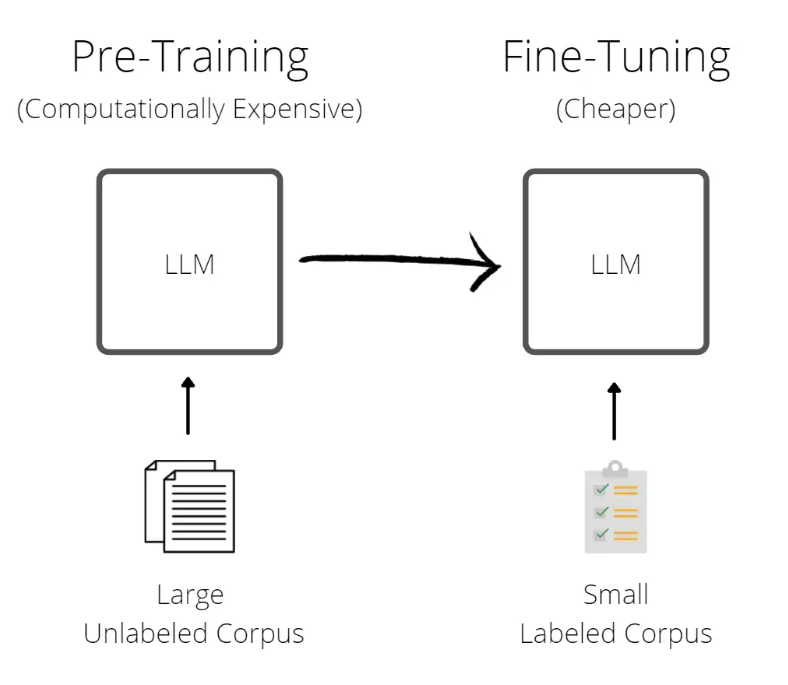
Figure 3: Pre-training vs. fine-tuning, Source: medium.com
一旦对模型进行了预训练,就可以使用特定于任务的新数据对其进行训练,以针对特定的用例对其进行微调。微调方法具有很高的计算效率,因为它需要更少的数据和功率,使其成为一种更便宜的方法(见图3)。
For more information, check our “Large Language Model Training in 2023” article.
大型语言模型的4个好处
1-减少人工和成本
语言模型可以用于自动化许多过程,例如:
- 情绪分析
- 客户服务
- 内容创建
- 欺诈检测
- 预测和分类
- 自动化这样的任务可以减少人工和相关成本
2-提高可用性、个性化和客户满意度
许多客户希望企业全天候可用,这可以通过使用语言模型的聊天机器人和虚拟助理实现。通过自动化的内容创建,语言模型可以通过处理大量数据来了解客户的行为和偏好,从而推动个性化。客户满意度和积极的品牌关系将随着可用性和个性化服务的增加而增加。
3-节省时间
语言模型系统可以使营销、销售、人力资源和客户服务中的许多流程自动化。例如,语言模型可以帮助数据输入、客户服务和文档创建,让员工能够从事更重要的需要人工专业知识的任务
语言模型可以为企业节省时间的另一个领域是对大量数据的分析。凭借处理大量信息的能力,企业可以从复杂的数据集中快速提取见解,并做出明智的决策。这可以提高运营效率,更快地解决问题,并做出更明智的业务决策。
4-提高任务的准确性
大型语言模型能够处理大量数据,从而提高预测和分类任务的准确性。模型利用这些信息来学习模式和关系,这有助于他们做出更好的预测和分组。
例如,在情绪分析中,大型语言模型可以分析数千条客户评论,以了解每条评论背后的情绪,从而提高确定客户评论是正面、负面还是中性的准确性。这种提高的准确性在许多业务应用程序中至关重要,因为小错误可能会产生重大影响。
语言模型的挑战和局限性
1-可靠性和偏差
语言模型的能力仅限于使用文本训练数据进行训练,这意味着他们对世界的了解有限。模型学习训练数据中的关系,这些关系可能包括:
- 虚假信息
- 种族、性别和性别偏见
- 恶毒的语言
当训练数据没有经过检查和标记时,语言模型会发表种族主义或性别歧视的言论
在某些情况下,模型可能会提供虚假信息。
2-上下文窗口
每个大型语言模型只有一定的内存,因此它只能接受一定数量的令牌作为输入。例如,ChatGPT有2048个令牌(约1500个单词)的限制,这意味着ChatGPT无法理解输入,也无法为超过2048个令牌限制的输入生成输出
3-系统成本
开发大型语言模型需要以计算机系统、人力资本(工程师、研究人员、科学家等)和权力的形式进行大量投资。由于资源密集,大型语言模型的开发只能用于拥有大量资源的大型企业。据估计,来自NVIDIA和微软的威震天图灵的项目总成本接近1亿美元。2
4-环境影响
Megatron-Turing是由数百台NVIDIA DGX A100多GPU服务器开发的,每台服务器的功耗高达6.5千瓦。除了大量的动力来冷却这个巨大的框架外,这些模型还需要大量的动力,并留下大量的碳足迹。
根据一项研究,在GPU上训练BERT(谷歌LLM)大致相当于一次跨美国飞行。3
参考资料
This article was drafted by former AIMultiple industry analyst Berke Can Agagündüz.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017, December 6). “Attention is All You Need“. arXiv.org. Retrieved February 10, 2023, from https://arxiv.org/abs/1706.03762
- Simon, J. (October 26, 2021). “Large Language Models: A New Moore’s Law?“. Hugging Face – The AI community building the future. Retrieved February 10, 2023, from https://huggingface.co/blog/large-language-models
- Strubell, E., Ganesh, A., & McCallum, A. (2019, June 5). “Energy and Policy Considerations for Deep Learning in NLP“. arXiv.org. Retrieved February 10, 2023, from https://arxiv.org/abs/1906.02243
- 登录 发表评论