
【ChatGTP】驯服魔鬼:使用ChatGPT简化软件开发
纵观历史,魔鬼和恶魔的故事一直是民间传说和神话的主要内容。狡猾的巫师驯服这些强大的生物来执行他们的命令的故事吸引了几代观众。
让我们从一个关于狡猾的魔鬼和聪明的巫师的简短故事开始。
从前,在两座高耸的山脉之间的一个小村庄里,住着一位名叫阿拉里克的聪明的老巫师。在一个决定性的日子里,阿拉里克的任务是制造一种药水,可以治愈肆虐附近土地的可怕瘟疫。然而,关键成分,一种罕见的金色草本植物,只能在闹鬼的森林中找到。
阿拉里克为了拯救他的人民,不顾一切地召唤了一个狡猾的魔鬼泽菲罗斯,并达成了协议。作为Zephyros在危险的森林中航行和取回金色草药的帮助的交换,巫师承诺将魔鬼从一个世纪的奴役中释放出来。凭借魔鬼的指引和无与伦比的敏捷,阿拉里克冒着森林中的重重陷阱和危险,最终获得了难以捉摸的金色草药。
他们一起回到了村庄,阿拉里克在那里成功地酿造了救命药,结束了这场毁灭性的瘟疫。巫师信守诺言,将泽菲罗斯从束缚中释放出来,魔鬼和巫师对彼此的能力和决心都获得了新的尊重。
这个故事的寓意强调了相互尊重和合作的重要性。虽然魔鬼拥有独特的能力,但它需要我们的帮助才能完成任务。通过共同努力,我们可以更有效地实现我们的目标。
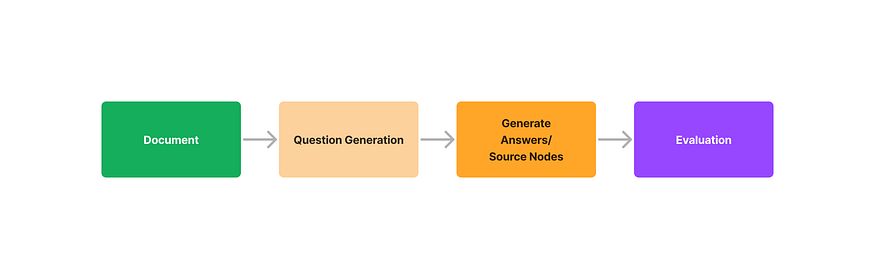
【LLM】用LlamaIndex建立和评估QA保证体系
介绍
LlamaIndex(GPT Index)提供了一个将大型语言模型(LLM)与外部数据连接起来的接口。LlamaIndex提供了各种数据结构来索引数据,如列表索引、向量索引、关键字索引和树索引。它提供了高级API和低级API——高级API允许您仅用五行代码构建问题解答(QA)系统,而低级API允许您定制检索和合成的各个方面。
然而,将这些系统投入生产需要仔细评估整个系统的性能,即给定输入的输出质量。检索增强生成的评估可能具有挑战性,因为用户需要针对给定的上下文提出相关问题的数据集。为了克服这些障碍,LlamaIndex提供了问题生成和无标签评估模块。
在本博客中,我们将讨论使用问题生成和评估模块的三步评估过程:
- 从文档生成问题
- 使用LlamaIndex QueryEngine抽象生成问题的答案/源节点,该抽象管理LLM和数据索引之间的交互。
- 评估问题(查询)、答案和源节点是否匹配/内联
【OpenAI】我如何使用OpenAI将公司的文档转化为可搜索数据库
以及如何对您的文档进行同样的处理
在过去的六个月里,我一直在一个初创公司Voxel51工作,该公司是开源计算机视觉工具包FiftyOne的创始人。作为一名机器学习工程师和开发人员,我的工作是倾听我们的开源社区,并为他们带来他们需要的东西——新功能、集成、教程、研讨会,你能想到的。
几周前,我们在FiftyOne中添加了对矢量搜索引擎和文本相似性查询的原生支持,这样用户就可以通过简单的自然语言查询在他们的(通常是海量的,包含数百万或数千万个样本)数据集中找到最相关的图像。
这让我们陷入了一个奇怪的境地:现在,使用开源FiftyOne的人可以通过自然语言查询轻松搜索数据集,但使用我们的文档仍然需要传统的关键字搜索。
我们有很多文档,这些文档有其优点和缺点。作为一名用户,我有时会发现,考虑到文档的数量,准确地找到我想要的内容需要比我想要的更多的时间。
【ChatGPT 】如何使用自定义知识库构建自己的自定义ChatGPT
ChatGPT已经成为大多数人每天用来自动化各种任务的不可或缺的工具。如果你使用过ChatGPT任何一段时间,你都会意识到它可能会提供错误的答案,并且在一些小众主题上限制为零上下文。这就提出了一个问题,即我们如何利用chatGPT来弥合差距,并允许chatGPT拥有更多的自定义数据。
丰富的知识分布在我们日常互动的各种平台上,即通过工作中的融合wiki页面、松弛组、公司知识库、Reddit、Stack Overflow、书籍、时事通讯和同事共享的谷歌文档。掌握所有这些信息来源本身就是一项全职工作。
如果你能有选择地选择你的数据源,并将这些信息轻松地输入到ChatGPT与你的数据的对话中,那不是很好吗?
1.通过Prompt Engineering提供数据
在我们讨论如何扩展ChatGPT之前,让我们看看如何手动扩展ChatGPT以及存在哪些问题。扩展ChatGPT的传统方法是通过即时工程(prompt engineering)。
这很简单,因为ChatGPT是上下文感知的。首先,我们需要通过在实际问题之前附加原始文档内容来与ChatGPT进行交互。
【ChatGPT 】如何使用自己的数据创建私人ChatGPT
了解使用ChatGPT/LLM创建自己的问答引擎所需的体系结构和数据要求。
开发工具
- 阅读更多 关于 开发工具
- 登录 发表评论
【开发工具】11 VS每个Web开发人员都应该拥有的代码扩展
扩展使我们能够修改和增加开发经验,同时提高生产力。
【React】React的18个最佳实践
Code it better
![]()
【Angular 】构建可扩展Angular 应用程序的10个最佳实践-附示例
Angular is a popular front-end web development framework that provides a robust set of features and tools to build scalable web applications. However, building scalable Angular applications can be a daunting task. In this article, we will discuss 10 best practices for building scalable Angular applications, along with code examples, explanations, and examples of bad practices to avoid.
【Angular】Angular中结构管道

What is Angular Pipe?
A pipe takes in data as input and transforms it into an output. The pipe’s purpose is to allow the transformation of an existing value and reusability!