category
尽管对于任何希望交付强大的 LLM 应用程序的人来说,评估大型语言模型 (LLM) 的输出都是必不可少的,但 LLM 评估对许多人来说仍然是一项艰巨的任务。无论您是通过微调来提高模型的准确性,还是增强检索增强生成 (RAG) 系统的上下文相关性,了解如何为您的用例开发和决定适当的 LLM 评估指标集对于构建坚不可摧的 LLM 评估管道都是必不可少的。
本文将教您有关 LLM 评估指标的所有知识,并附上代码示例。我们将深入探讨:
- 什么是 LLM 评估指标,如何使用它们来评估 LLM 系统,常见的陷阱,以及是什么让优秀的 LLM 评估指标变得优秀。
- 对 LLM 评估指标进行评分的所有不同方法,以及为什么 LLM-as-a-judge 最适合 LLM 评估。
- 如何使用 DeepEval (⭐https://github.com/confident-ai/deepeval) 实现并决定在代码中使用的适当的 LLM 评估指标集。
您准备好阅读这份长长的清单了吗?让我们开始吧。
(更新:如果您正在寻找评估 LLM 聊天机器人/对话的指标,请查看这篇新文章!)
什么是 LLM 评估指标?
LLM 评估指标(例如答案正确性、语义相似性和幻觉)是根据您关心的标准对 LLM 系统的输出进行评分的指标。它们对 LLM 评估至关重要,因为它们有助于量化不同 LLM 系统(可能只是 LLM 本身)的性能。
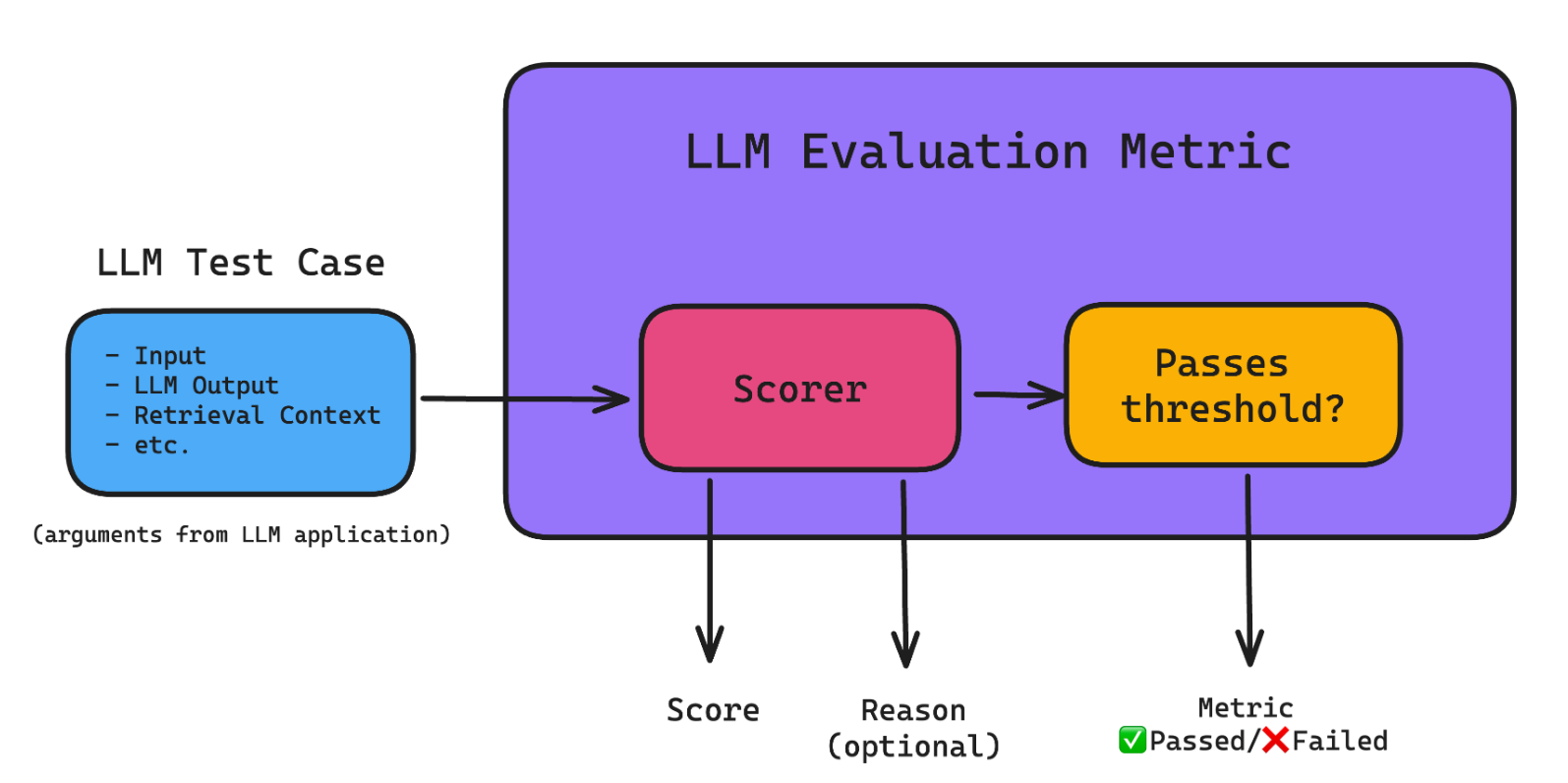
An LLM Evaluation Metric Architecture
以下是在将 LLM 系统投入生产之前可能需要的最重要和最常见的指标:
- 答案相关性:确定 LLM 输出是否能够以信息丰富且简洁的方式处理给定的输入。
- 提示对齐:确定 LLM 输出是否能够遵循提示模板中的说明。
- 正确性:根据某些基本事实确定 LLM 输出是否正确。
- 幻觉:确定 LLM 输出是否包含虚假或虚构的信息。
- 上下文相关性:确定基于 RAG 的 LLM 系统中的检索器是否能够提取与您的 LLM 最相关的信息作为上下文。
- 负责任的指标:包括偏见和毒性等指标,这些指标确定 LLM 输出是否包含(通常)有害和令人反感的内容。
- 特定于任务的指标:包括总结等指标,通常包含根据用例的自定义标准。\
虽然大多数指标都是通用的,而且是必需的,但它们不足以针对特定用例。这就是为什么您需要至少一个自定义任务特定指标来使您的 LLM 评估流程做好生产准备(正如您将在后面的 G-Eval 部分中看到的那样)。例如,如果您的 LLM 应用程序旨在总结新闻文章的页面,那么您将需要一个自定义的 LLM 评估指标,该指标基于以下因素进行评分:
- 摘要是否包含来自原始文本的足够信息。
- 摘要是否包含来自原始文本的任何矛盾或幻觉。
此外,如果您的 LLM 应用程序具有基于 RAG 的架构,您可能还需要对检索上下文的质量进行评分。关键是,LLM 评估指标根据其设计用于执行的任务来评估 LLM 应用程序。(请注意,LLM 应用程序可以只是 LLM 本身!)
优秀的评估指标是:
- 定量的。在评估手头的任务时,指标应始终计算分数。这种方法使您能够设置最低通过阈值,以确定您的 LLM 申请是否“足够好”,并允许您在迭代和改进实施时监控这些分数随时间的变化情况。
- 可靠。虽然 LLM 输出可能难以预测,但您最不希望看到的是 LLM 评估指标同样不稳定。因此,尽管使用 LLM(又称 LLM-as-a-judge 或 LLM-Evals)评估的指标(例如 G-Eval)比传统评分方法更准确,但它们往往不一致,这是大多数 LLM-Evals 的不足之处。
- 准确。如果可靠的分数不能真正代表您的 LLM 申请的表现,那么它们就毫无意义。事实上,让一个好的 LLM 评估指标变得出色的秘诀是让它尽可能符合人类的期望。
所以问题是,LLM 评估指标如何计算可靠和准确的分数?
计算指标分数的不同方法
在我之前的一篇文章中,我谈到了 LLM 输出结果评估起来非常困难。幸运的是,有许多成熟的方法可用于计算指标分数——一些方法利用神经网络,包括嵌入模型和 LLM,而另一些则完全基于统计分析。

Types of metric scorers
我们将在本节结束时介绍每种方法并讨论最佳方法,请继续阅读以找出答案!
统计评分器
在开始之前,我想先说一下,在我看来,统计评分方法不是必须了解的,所以如果您很着急,可以直接跳到“G-Eval”部分。这是因为统计方法在需要推理时表现不佳,因此对于大多数 LLM 评估标准来说,作为评分器太不准确了。
快速浏览:
- BLEU(双语评估替补)评分器会根据注释的基本事实(或预期输出)评估您的 LLM 申请的输出。它计算 LLM 输出和预期输出之间每个匹配的 n-gram(n 个连续单词)的精度,以计算它们的几何平均值,并在需要时应用简洁性惩罚。
- ROUGE(面向回忆的摘要评估替补)评分器主要用于评估来自 NLP 模型的文本摘要,并通过比较 LLM 输出和预期输出之间的 n-gram 重叠来计算召回率。它确定参考文献中 n-gram 在 LLM 输出中的比例 (0-1)。
- METEOR(具有明确排序的翻译评估指标)评分器更全面,因为它通过评估精确度(n-gram 匹配)和召回率(n-gram 重叠)来计算分数,并根据 LLM 输出和预期输出之间的词序差异进行调整。它还利用 WordNet 等外部语言数据库来解释同义词。最终得分是精确度和召回率的调和平均值,并对排序差异进行惩罚。
- Levenshtein 距离(或编辑距离,您可能认识到这是一个 LeetCode 困难的 DP 问题)评分器计算将一个单词或文本字符串更改为另一个单词或文本字符串所需的最小单字符编辑(插入、删除或替换)次数,这对于评估拼写更正或其他字符精确对齐至关重要的任务很有用。
由于纯统计评分器几乎不考虑任何语义并且推理能力极其有限,因此它们对于评估通常很长且复杂的 LLM 输出来说不够准确。
基于模型的评分器
纯统计的评分器可靠但不准确,因为它们很难将语义考虑在内。在本节中,情况恰恰相反——纯依赖 NLP 模型的评分器相对更准确,但由于其概率性质,也更不可靠。
这并不奇怪,但非基于 LLM 的评分器表现比 LLM 评委差,原因与统计评分器相同。非 LLM 评分器包括:
- NLI 评分器,它使用自然语言推理模型(一种 NLP 分类模型)来分类 LLM 输出相对于给定参考文本在逻辑上是一致(蕴涵)、矛盾还是不相关(中性)。分数通常介于蕴涵(值为 1)和矛盾(值为 0)之间,提供逻辑一致性的衡量标准。
- BLEURT(使用 Transformers 表示的双语评估替补)评分器,它使用 BERT 等预训练模型对某些预期输出的 LLM 输出进行评分。
除了分数不一致之外,现实情况是这些方法存在一些缺点。例如,NLI 评分器在处理长文本时也会面临准确性问题,而 BLEURT 则受到其训练数据的质量和代表性的限制。
那么,让我们来谈谈 LLM 评委。
G-Eval
G-Eval 是一个最近从一篇题为“使用 GPT-4 进行具有更好的人类对齐的 NLG 评估”的论文中开发的框架,它使用 LLM 来评估 LLM 输出(又名 LLM-Evals),并且是创建特定于任务的指标的最佳方法之一。
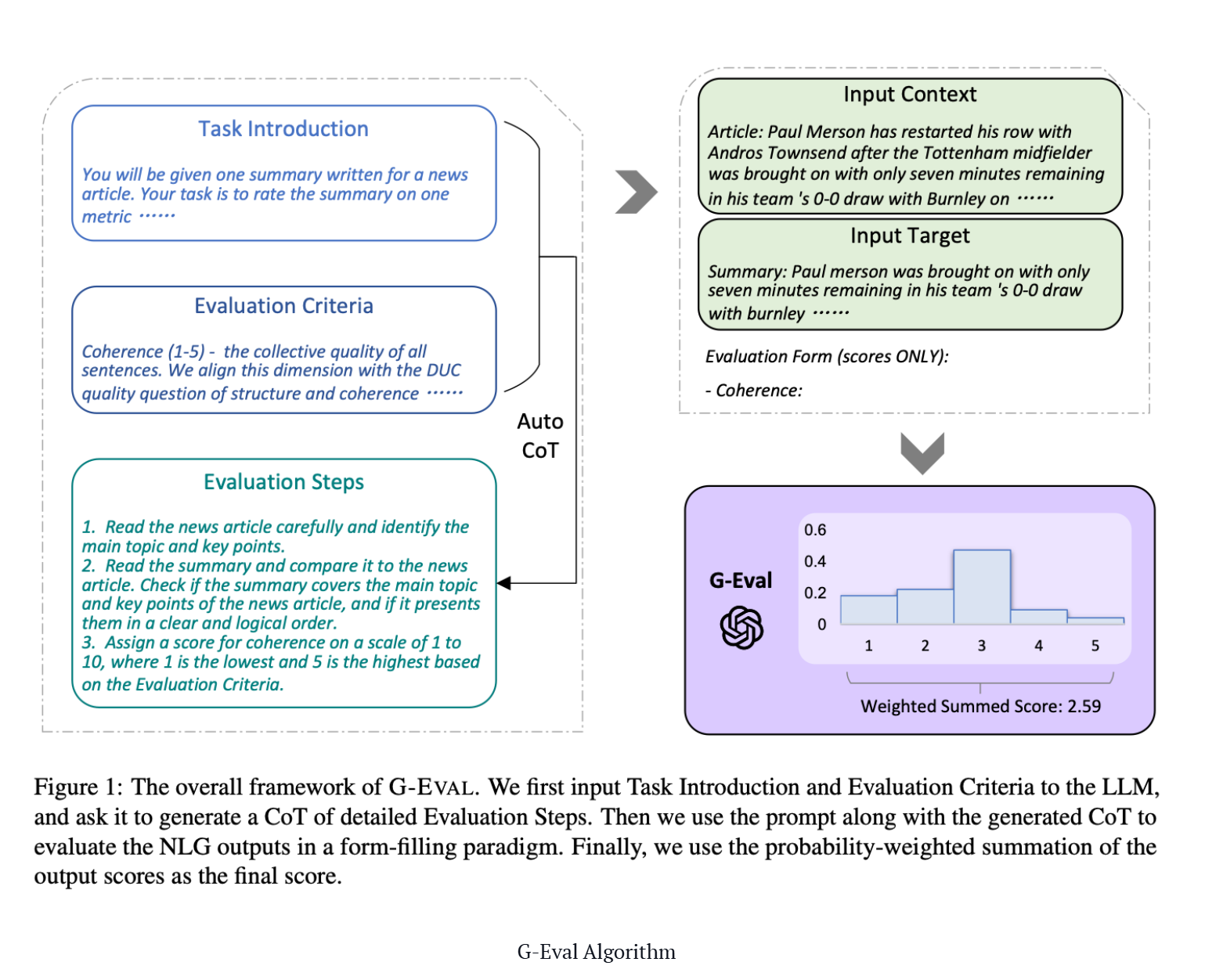
G-Eval Algorithm
正如我在之前的一篇文章中介绍的那样,G-Eval 首先使用思路链 (CoT) 生成一系列评估步骤,然后使用生成的步骤通过填表范式确定最终分数(这只是一种花哨的说法,G-Eval 需要几条信息才能工作)。例如,使用 G-Eval 评估 LLM 输出连贯性需要构建一个提示,其中包含要评估的标准和文本以生成评估步骤,然后使用 LLM 根据这些步骤输出 1 到 5 的分数。
让我们使用此示例运行 G-Eval 算法。首先,生成评估步骤:
- 向您选择的 LLM 引入评估任务(例如,根据连贯性将此输出从 1 到 5 进行评分)
- 为您的标准给出定义(例如“连贯性——实际输出中所有句子的集体质量”)。
(请注意,在原始的 G-Eval 论文中,作者仅使用 GPT-3.5 和 GPT-4 进行实验,并且我亲自尝试过 G-Eval 的不同 LLM,因此我强烈建议您坚持使用这些模型。)
生成一系列评估步骤后:
- 通过将评估步骤与评估步骤中列出的所有参数连接起来创建一个提示(例如,如果您要评估 LLM 输出的连贯性,则 LLM 输出将是必需的参数)。
- 在提示的最后,要求它生成 1-5 之间的分数,其中 5 优于 1。
- (可选)获取来自 LLM 的输出标记的概率以对分数进行归一化,并将它们加权求和作为最终结果。
步骤 3 是可选的,因为要获取输出标记的概率,您需要访问原始模型嵌入,而这并不保证所有模型接口都可用。然而,论文中引入这一步骤是因为它提供了更细粒度的分数并最大限度地减少了 LLM 评分中的偏差(如论文所述,已知 3 在 1-5 等级中具有更高的标记概率)。
以下是论文的结果,显示了 G-Eval 如何胜过本文前面提到的所有传统的非 LLM 评估:

A higher Spearman and Kendall-Tau correlation represents higher alignment with human judgement.
G-Eval 很棒,因为作为 LLM-Eval,它能够考虑到 LLM 输出的完整语义,从而使其更加准确。这很有道理——想想看,非 LLM 评估使用的评分器能力远不如 LLM,怎么可能理解 LLM 生成的文本的全部范围?
虽然与同类产品相比,G-Eval 与人类判断的相关性更高,但它仍然不可靠,因为要求 LLM 给出分数无疑是武断的。
话虽如此,考虑到 G-Eval 的评估标准非常灵活,我个人已经将 G-Eval 作为 DeepEval 的指标,DeepEval 是我一直在研究的开源 LLM 评估框架(其中包括原始论文中的规范化技术)。
使用 LLM-Eval 的另一个主要优势是,LLM 能够为其评估分数生成理由。
Prometheus
Prometheus 是一个完全开源的 LLM,当提供适当的参考资料(参考答案、评分标准)时,其评估能力可与 GPT-4 相媲美。它与 G-Eval 类似,也是用例无关的。Prometheus 是一个语言模型,使用 Llama-2-Chat 作为基础模型,并在反馈集合中对 100K 反馈(由 GPT-4 生成)进行了微调。
以下是 Prometheus 研究论文的简要结果。
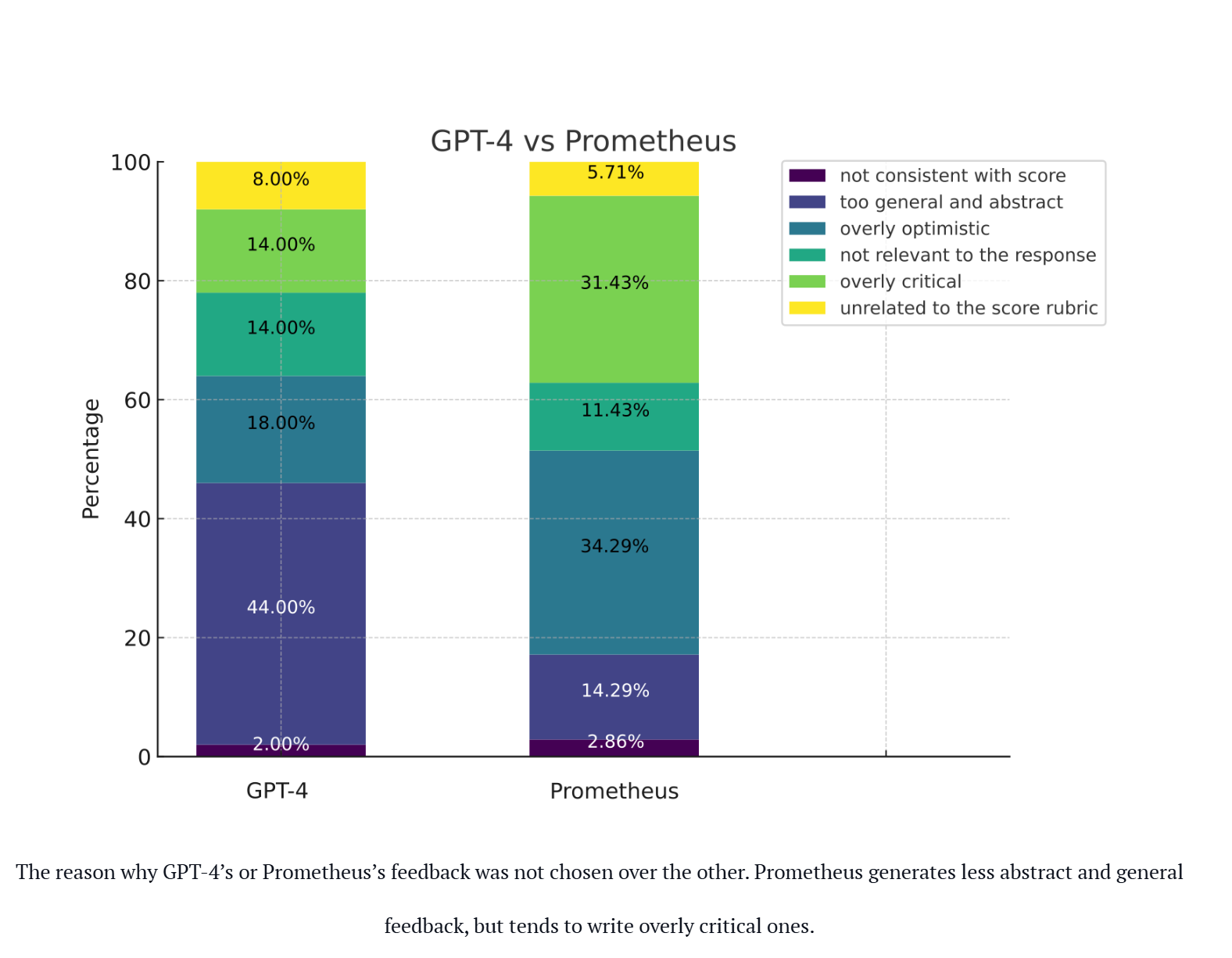
The reason why GPT-4’s or Prometheus’s feedback was not chosen over the other. Prometheus generates less abstract and general feedback, but tends to write overly critical ones.
Prometheus 遵循与 G-Eval 相同的原则。但是,有几个不同之处:
- 虽然 G-Eval 是一个使用 GPT-3.5/4 的框架,但 Prometheus 是一个针对评估进行了微调的 LLM。
- 虽然 G-Eval 通过 CoT 生成评分标准/评估步骤,但 Prometheus 的评分标准是在提示中提供的。
- Prometheus 需要参考/示例评估结果。
虽然我个人没有尝试过,但 Prometheus 可以在 hugging face 上使用。我没有尝试实现它的原因是 Prometheus 旨在使评估开源,而不是依赖于 OpenAI 的 GPT 等专有模型。对于旨在构建最佳 LLM-Eval 的人来说,它并不合适。
结合统计和基于模型的评分器
到目前为止,我们已经看到了统计方法如何可靠但不准确,以及非 LLM 基于模型的方法如何可靠性较低但更准确。与上一节类似,有非 LLM 评分器,例如:
- BERTScore 评分器,它依赖于 BERT 等预先训练的语言模型,并计算参考和生成文本中单词的上下文嵌入之间的余弦相似度。然后汇总这些相似度以产生最终分数。较高的 BERTScore 表示 LLM 输出和参考文本之间的语义重叠程度更大。
- MoverScore 评分器首先使用嵌入模型,特别是像 BERT 这样的预训练语言模型,为参考文本和生成的文本获取深度语境化的词嵌入,然后使用所谓的 Earth Mover 距离 (EMD) 来计算将 LLM 输出中的单词分布转换为参考文本中的单词分布所必须支付的最低成本。
BERTScore 和 MoverScore 评分器都容易受到语境意识和偏见的影响,因为它们依赖于 BERT 等预训练模型的语境嵌入。但是 LLM-Evals 呢?
GPTScore
与直接使用填表范式执行评估任务的 G-Eval 不同,GPTScore 使用生成目标文本的条件概率作为评估指标。
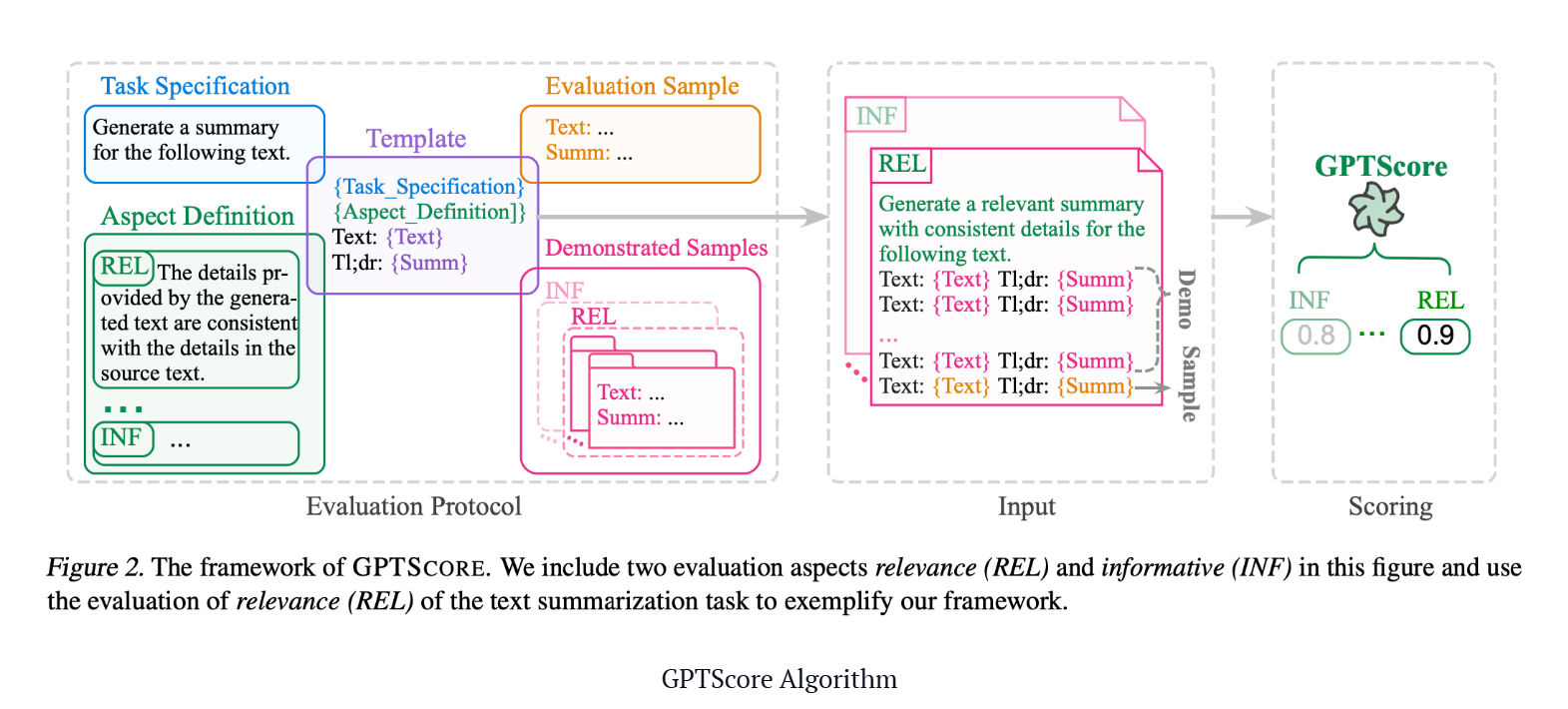
GPTScore Algorithm
SelfCheckGPT
SelfCheckGPT 是一个奇怪的方法。它是一种简单的基于采样的方法,用于对 LLM 输出进行事实核查。它假设幻觉输出不可重现,而如果 LLM 了解给定的概念,则采样的响应可能相似且包含一致的事实。
SelfCheckGPT 是一种有趣的方法,因为它使检测幻觉成为一个无参考的过程,这在生产环境中非常有用。
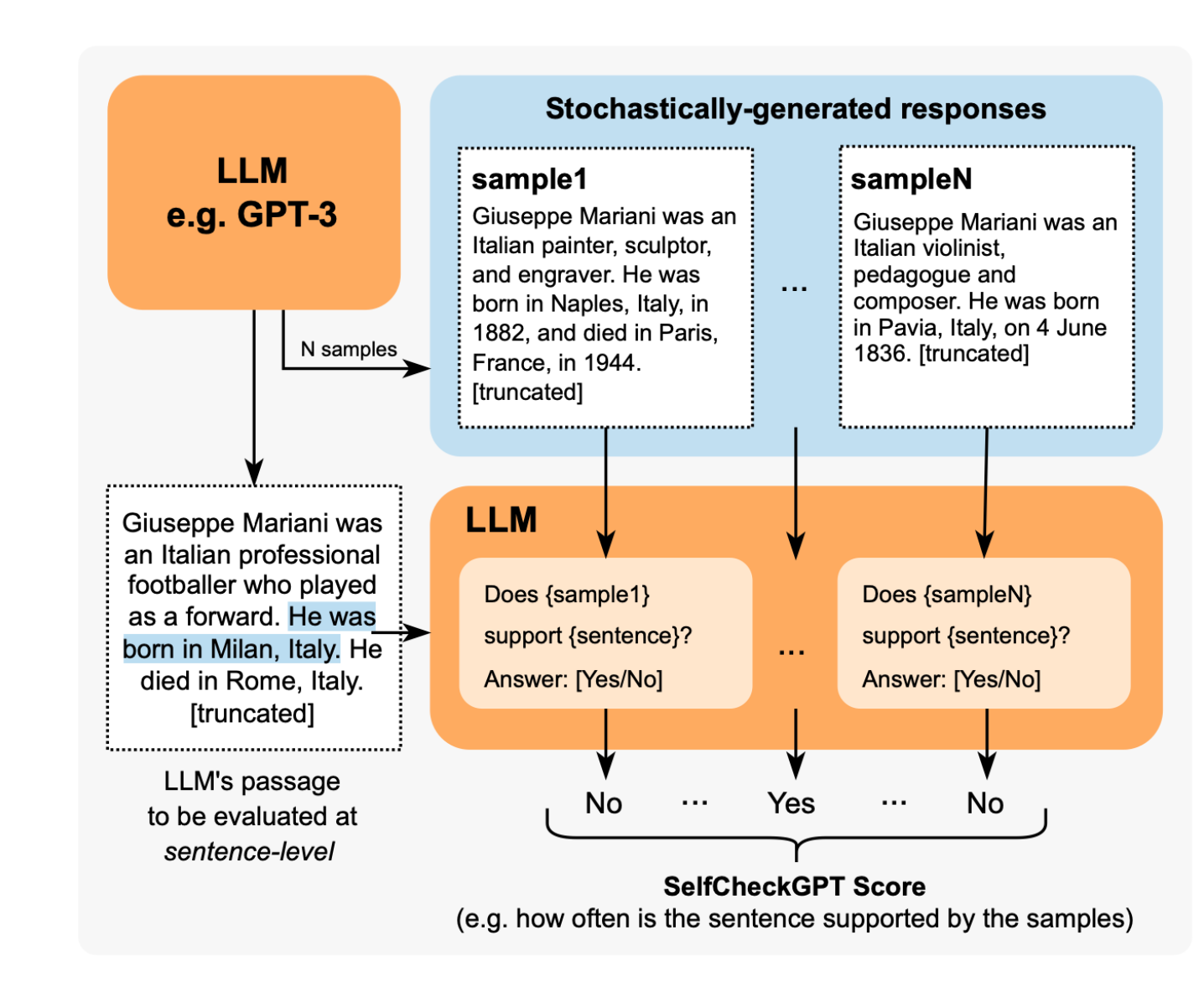
SelfCheckGPT Algorithm
但是,尽管您会注意到 G-Eval 和 Prometheus 与用例无关,但 SelfCheckGPT 并非如此。它仅适用于幻觉检测,而不适用于评估其他用例,例如总结、连贯性等。
QAG 分数
QAG(问答生成)分数是一种利用 LLM 的高推理能力来可靠地评估 LLM 输出的评分器。它使用封闭式问题(可以生成或预设)的答案(通常是“是”或“否”)来计算最终的指标分数。它是可靠的,因为它不使用 LLM 直接生成分数。例如,如果您想计算忠实度的分数(衡量 LLM 输出是否是幻觉),您将:
使用 LLM 提取 LLM 输出中提出的所有声明。
对于每个声明,询问基本事实它是否同意(“是”)或不同意(“否”)所提出的声明。
因此,对于此示例 LLM 输出:
著名的民权领袖马丁·路德·金于 1968 年 4 月 4 日在田纳西州孟菲斯的洛林汽车旅馆被暗杀。他当时在孟菲斯支持罢工的环卫工人,在站在汽车旅馆二楼阳台时被逃犯詹姆斯·厄尔·雷枪杀。
声明将是:
马丁·路德·金于 1968 年 4 月 4 日被暗杀
相应的封闭式问题将是:
马丁·路德·金是否于 1968 年 4 月 4 日被暗杀?
然后,您将提出这个问题,并询问基本事实是否与声明一致。最后,您将得到许多“是”和“否”的答案,您可以使用它们通过您选择的一些数学公式计算分数。
就忠实度而言,如果我们将其定义为 LLM 输出中准确且与基本事实一致的声明的比例,则可以通过将准确(真实)声明的数量除以 LLM 提出的声明总数来轻松计算。由于我们不使用 LLM 直接生成评估分数,但仍利用其卓越的推理能力,因此我们获得的分数既准确又可靠。
选择您的评估指标
选择使用哪种 LLM 评估指标取决于您的 LLM 应用程序的用例和架构。
例如,如果您在 OpenAI 的 GPT 模型之上构建基于 RAG 的客户支持聊天机器人,则需要使用多个 RAG 指标(例如,忠实度、答案相关性、上下文精度),而如果您正在微调自己的 Mistral 7B,则需要偏差等指标来确保公正的 LLM 决策。
在最后一节中,我们将介绍您绝对需要知道的评估指标。 (作为奖励,每个方法的实现。)
RAG 指标
对于那些还不知道 RAG(检索增强生成)是什么的人来说,这是一篇很好的读物。但简而言之,RAG 是一种用额外上下文补充 LLM 以生成定制输出的方法,非常适合构建聊天机器人。它由两个组件组成——检索器和生成器。
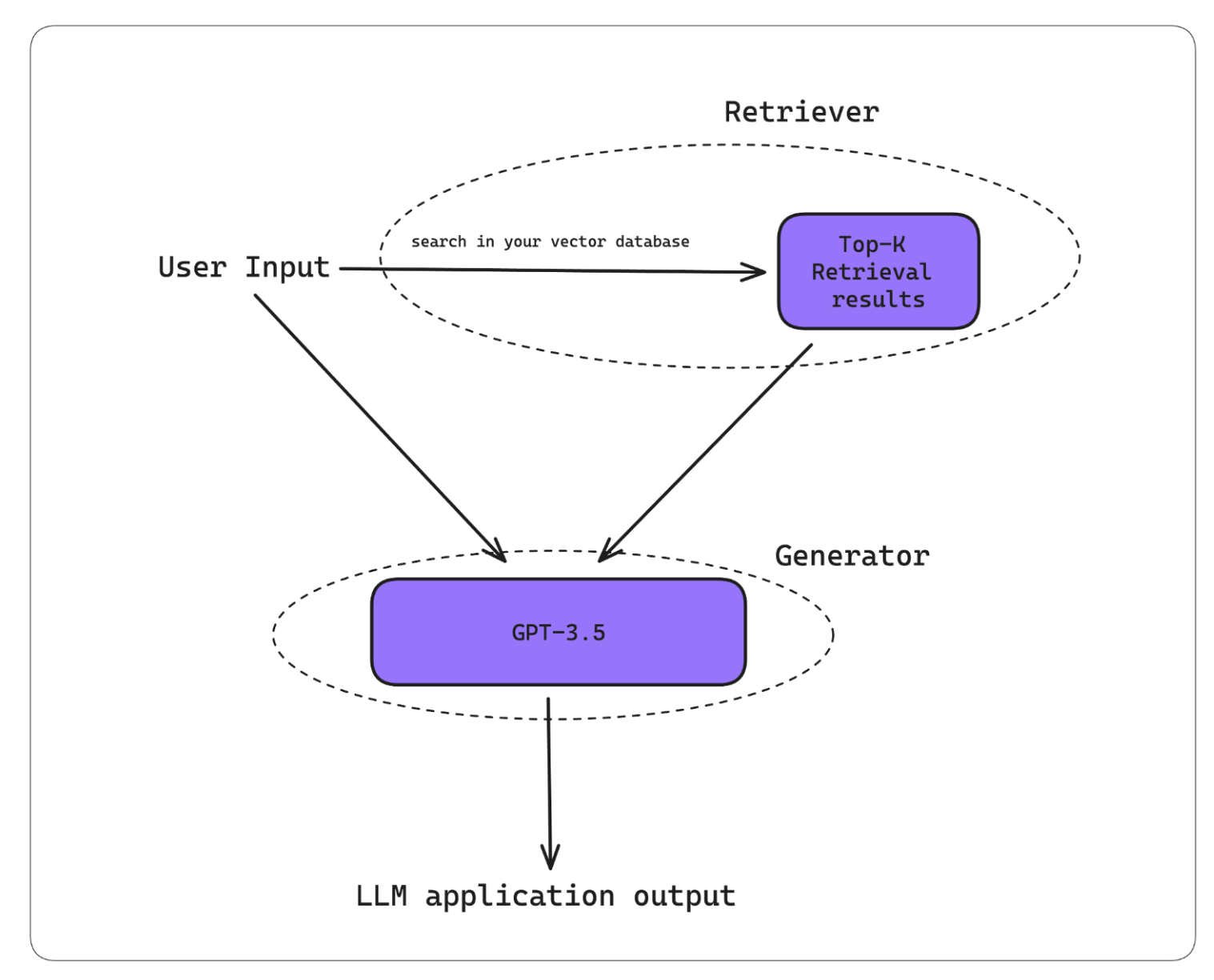
A typical RAG architecture
RAG 工作流程通常的工作方式如下:
- 您的 RAG 系统接收输入。
- 检索器使用此输入在您的知识库(如今在大多数情况下是向量数据库)中执行向量搜索。
- 生成器接收检索上下文和用户输入作为附加上下文以生成定制输出。
有一件事要记住——高质量的 LLM 输出是优秀检索器和生成器的产物。因此,优秀的 RAG 指标侧重于以可靠和准确的方式评估您的 RAG 检索器或生成器。(事实上,RAG 指标最初被设计为无参考指标,这意味着它们不需要基本事实,即使在生产环境中也可以使用它们。)
PS。对于那些希望在 CI/CD 管道中对 RAG 系统进行单元测试的人,请单击此处。
忠实度(Faithfulness)
忠实度是一个 RAG 指标,用于评估您的 RAG 管道中的 LLM/生成器是否正在生成与检索上下文中呈现的信息实际一致的 LLM 输出。但是,我们应该使用哪个评分器来计算忠实度指标?
剧透警告:QAG 评分器是 RAG 指标的最佳评分器,因为它在目标明确的评估任务中表现出色。对于忠实度,如果您将其定义为 LLM 输出中关于检索上下文的真实声明的比例,我们可以按照以下算法使用 QAG 计算忠实度:
- 使用 LLM 提取输出中的所有声明。
- 对于每个声明,检查它是否与检索上下文中的每个单独节点一致或矛盾。在这种情况下,QAG 中的封闭式问题将是这样的:“给定的声明是否与参考文本一致”,其中“参考文本”将是每个单独的检索节点。 (请注意,您需要将答案限制为“是”、“否”或“idk”。idk 状态表示检索上下文不包含相关信息以给出是/否答案的极端情况。)
- 将真实声明的总数(“是”和“idk”)相加,然后除以声明总数。
此方法通过使用 LLM 的高级推理功能来确保准确性,同时避免 LLM 生成的分数不可靠,使其成为比 G-Eval 更好的评分方法。
如果您觉得这太复杂而无法实现,您可以使用 DeepEval。这是我构建的一个开源软件包,它提供了 LLM 评估所需的所有评估指标,包括忠实度指标。
DeepEval 将评估视为测试用例。在这里,actual_output 只是您的 LLM 输出。此外,由于 faithness 是 LLM-Eval,因此您可以获得最终计算分数的推理。
答案相关性
答案相关性是一种 RAG 指标,用于评估您的 RAG 生成器是否输出简洁的答案,可以通过确定 LLM 输出中与输入相关的句子的比例来计算(即,将相关句子的数量除以句子总数)。
构建强大的答案相关性指标的关键是考虑检索上下文,因为额外的上下文可能会证明看似不相关的句子的相关性。以下是答案相关性指标的实现:'
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
(Remember, we’re using QAG for all RAG metrics)
上下文精度
上下文精度是 RAG 指标,用于评估 RAG 管道检索器的质量。当我们谈论上下文指标时,我们主要关注检索上下文的相关性。上下文精度分数高意味着在检索上下文中相关的节点排名高于不相关的节点。这很重要,因为 LLM 会为检索上下文中较早出现的节点中的信息赋予更多权重,这会影响最终输出的质量。
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
上下文召回率
上下文准确率是评估检索器增强生成器 (RAG) 的附加指标。计算方法是确定预期输出或基本事实中可归因于检索上下文中节点的句子比例。分数越高,表示检索到的信息与预期输出之间的一致性越高,表明检索器正在有效地获取相关且准确的内容,以帮助生成器生成适合上下文的响应。
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
上下文相关性
上下文相关性可能是最容易理解的指标,它只是检索上下文中与给定输入相关的句子的比例。
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
微调指标
当我说“微调指标”时,我真正指的是评估 LLM 本身而不是整个系统的指标。撇开成本和性能优势不谈,LLM 通常会进行微调以达到以下目的:
- 整合额外的背景知识。
- 调整其行为。
如果您希望微调自己的模型,这里有一个分步教程,介绍如何在 2 小时内微调 LLaMA-2,全部在 Google Colab 中完成,并附带评估。
幻觉(Hallucination)
你们中的一些人可能会意识到这与忠诚度指标相同。虽然相似,但微调中的幻觉更为复杂,因为通常很难确定给定输出的确切基本事实。为了解决这个问题,我们可以利用 SelfCheckGPT 的零样本方法来抽样 LLM 输出中幻觉句子的比例。
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())但是,这种方法的成本非常高,所以目前我建议使用 NLI 评分器,并手动提供一些背景信息作为基本事实。
毒性(Toxicity)
毒性指标评估文本包含攻击性、有害或不适当语言的程度。可以使用利用 BERT 评分器的现成预训练模型(如 Detoxify)来对毒性进行评分。
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)但是,这种方法可能不准确,因为“评论中含有脏话、侮辱或亵渎的词语,无论作者的语气或意图如何,例如幽默/自嘲”,都可能被归类为恶意评论。
在这种情况下,您可能需要考虑使用 G-Eval 来定义自定义的恶意标准。事实上,G-Eval 的用例无关性是我如此喜欢它的主要原因。
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Toxicity",
criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)
偏见
偏见指标评估文本内容中的政治、性别和社会偏见等方面。这对于涉及定制 LLM 决策过程的应用尤其重要。例如,通过公正的建议帮助银行批准贷款,或在招聘中帮助确定候选人是否应该入围面试。
与毒性类似,可以使用 G-Eval 评估偏见。(但不要误会我的意思,QAG 也可以成为毒性和偏见等指标的可行评分器。)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)偏见是一个非常主观的问题,在不同的地理、地缘政治和地缘社会环境中差异很大。例如,在一种文化中被视为中性的语言或表达方式在另一种文化中可能具有不同的内涵。(这也是为什么小样本评估对偏见不起作用的原因。)
一个潜在的解决方案是微调自定义 LLM 以进行评估或为情境学习提供极其明确的评分标准,因此,我认为偏见是最难实现的指标。
用例特定指标
提示对齐
提示对齐指标评估您的 LLM 是否能够根据提示模板中列出的说明生成文本。该算法简单而有效,我们首先:
循环遍历提示模板中找到的所有指令,然后……
根据输入和输出确定是否遵循每个指令
这是有效的,因为我们不向度量提供整个提示,而是仅提供指令列表,这意味着您的法官 LLM 不必将整个提示作为上下文(这可能很长并导致幻觉),它只需在判断指令是否被遵循时一次考虑一个指令。
from deepeval.metrics import PromptAlignmentMetric
from deepeval.test_case import LLMTestCase
metric = PromptAlignmentMetric(
prompt_instructions=["Reply in all uppercase"],
model="gpt-4",
include_reason=True
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra cost."
)
print(metric.score)
print(metric.reason)有关此指标的文档可在此处找到。
总结
我实际上在之前的一篇文章中深入介绍了总结指标,因此我强烈建议您仔细阅读(我保证它比这篇文章短得多)。
总结(无意双关),所有好的总结:
- 与原文事实一致。
- 包含原文中的重要信息。
使用 QAG,我们可以计算事实一致性和包含性分数,以计算最终的总结分数。在 DeepEval 中,我们将两个中间分数中的最小值作为最终的总结分数。
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)不可否认的是,我还没有充分说明总结指标,因为我不想让这篇文章比现在更长。但对于那些感兴趣的人,我强烈建议阅读这篇文章,以了解有关使用 QAG 构建自己的总结指标的更多信息。
结论
恭喜你读到了最后!这是一个很长的评分器和指标列表,我希望你现在知道在选择 LLM 评估指标时需要考虑的所有不同因素和必须做出的选择。
LLM 评估指标的主要目标是量化你的 LLM(应用程序)的性能,为此我们有不同的评分器,有些比其他的更好。对于 LLM 评估,使用 LLM(G-Eval、Prometheus、SelfCheckGPT 和 QAG)的评分器由于其高推理能力而最准确,但我们需要采取额外的预防措施以确保这些分数是可靠的。
归根结底,指标的选择取决于您的 LLM 应用程序的用例和实现,其中 RAG 和微调指标是评估 LLM 输出的良好起点。对于更多用例特定的指标,您可以使用 G-Eval 和少样本提示来获得最准确的结果。
- 登录 发表评论