
【Angular 】Angular 模板中基于角色的访问控制
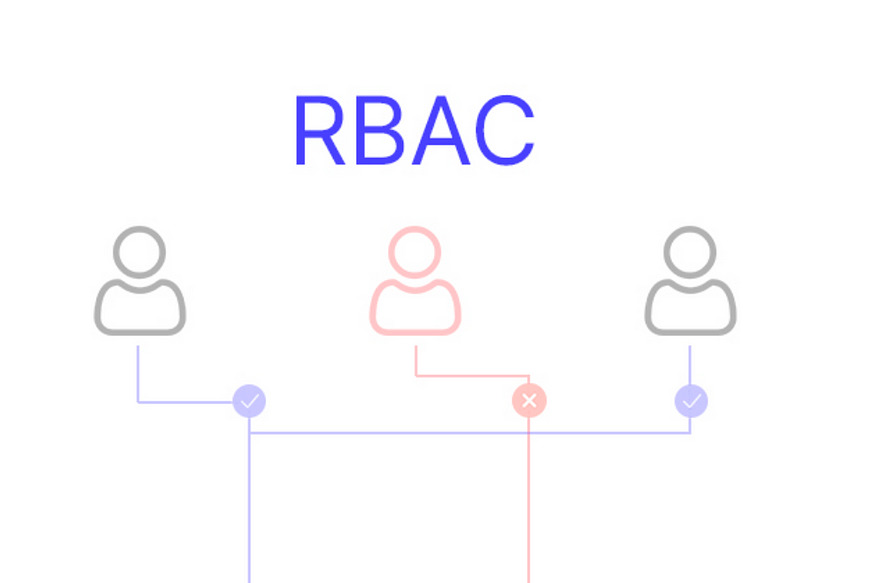
您是否在Angular模板中实现角色库访问控制?一种方法是通过*ngIf,但我不会选择该路径,因为它将在Angular模板中包含自定义函数,并且很难维护。正确的方法是使用Angular结构指令🚀.
什么是RBAC?
基于角色的访问控制(RBAC)是指根据用户在组织中的角色为其分配权限的想法。它提供了一种简单、可管理的访问管理方法,与单独为用户分配权限相比,这种方法更不容易出错。
实施
假设我们有一个具有3个属性的帐户接口:id、name和roles。角色是枚举类型的数组,可以表示我们的帐户可以具有的不同角色,包括ADMIN、USER、EDITOR、VIEWER。
【LangChain】与文档聊天:将OpenAI与LangChain集成的终极指南
欢迎来到人工智能的迷人世界,在那里,人与机器之间的通信越来越模糊。在这篇博客文章中,我们将探索人工智能驱动交互的一个令人兴奋的新前沿:与您的文本文档聊天!借助OpenAI模型和创新的LangChain框架的强大组合,您现在可以将静态文档转化为交互式对话。
你准备好彻底改变你使用文本文件的方式了吗?然后系好安全带,深入了解我们将OpenAI与LangChain集成的终极指南,我们将一步一步地为您介绍整个过程。
什么是LangChain?
LangChain是一个强大的框架,旨在简化大型语言模型(LLM)应用程序的开发。通过为各种LLM、提示管理、链接、数据增强生成、代理编排、内存和评估提供单一通用接口,LangChain使开发人员能够将LLM与真实世界的数据和工作流无缝集成。该框架允许LLM通过合并外部数据源和编排与不同组件的交互序列,更有效地解决现实世界中的问题。
我们将在下面的示例应用程序中使用该框架从文本文档源生成嵌入,并将这些内容持久化到Chroma矢量数据库中。然后,我们将使用LangChain在后台使用OpenAI语言模型来查询用户提供的问题,以处理请求。
这将使我们能够与自己的文本文档聊天。
【privateGPT】使用privateGPT训练您自己的LLM
了解如何在不向提供商公开您的私人数据的情况下训练您自己的语言模型
使用OpenAI的ChatGPT等公共人工智能服务的主要担忧之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用人工智能技术的公司最大的担忧。
很多时候,你想创建自己的语言模型,根据你的数据集(如销售见解、客户反馈等)进行训练,但同时你不想将所有这些敏感数据暴露给OpenAI等人工智能提供商。因此,理想的方法是在本地训练自己的LLM,而无需将数据上传到云。
如果你的数据是公开的,并且你不介意将它们暴露给ChatGPT,我有另一篇文章展示了如何将ChatGPT与你自己的数据连接起来:
【LLM】微调我的第一个WizardLM LoRA
根据特定用例调整LLM的行为
之前,我写过关于与Langchain和Vicuna等当地LLM一起创建人工智能代理的文章。如果你不熟悉这个话题,并且有兴趣了解更多,我建议你阅读我之前的文章,开始学习。
今天,我将这个想法向前推进几步。
首先,我们将使用一个更强大的模型来与Langchain Zero Shot ReAct工具一起使用,即WizardLM 7b模型。
其次,我们将使用LLM中的几个提示来生成一个数据集,该数据集可用于微调任何语言模型,以了解如何使用Langchain Python REPL工具。在这个例子中,我们将使用我的羊驼lora代码库分支来微调WizardLM本身。
我们为什么要这样做?因为不幸的是,大多数模型都不擅长在Langchain库中使用更复杂的工具,我们希望对此进行改进。我们的最终目标是让本地LLM使用Langchain工具高效运行,而不需要像我们目前需要的那样进行过多提示。
总之,以下是本文的部分:
【低代码平台】10个开源免费Airtable 的替代方案
Airtable是一个易于使用的简单低代码平台,有助于团队协作管理复杂的数据表,并创建定制的工作流程。把它想象成一个类固醇上的云电子表格。
Airtable还简化了数据输入过程,连接和集成第三方服务和应用程序,并提供了许多数据导入/导出选项。
使用它,您可以创建自定义接口、窗体和视图,以插入、管理和查看数据。它还包含图表、时间线、日历、地图、资产和图像管理器。
然而,作为一个托管服务,您无法控制您的数据,许多人可能会发现这是有限制的。因此,我们在这里为您提供了最好的Airtable低代码替代方案,几乎可以做到这一点。
如果您正在寻找SQL低代码数据库管理应用程序,我们在以下文章中介绍了您:
【LLM 】7个基本的NLP模型,为ML应用程序赋能
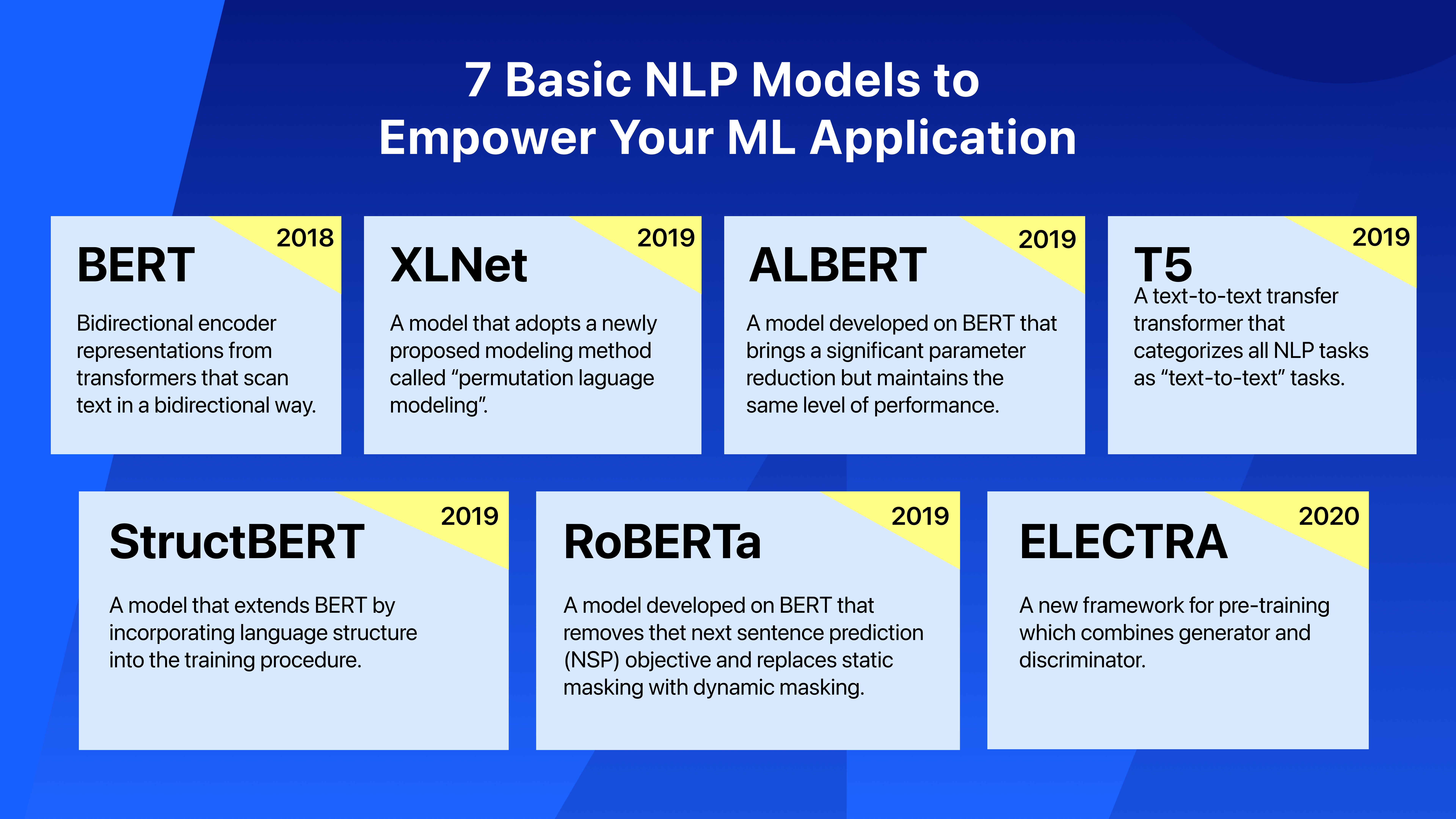
在上一篇文章中,我们已经解释了什么是NLP及其在现实世界中的应用。在这篇文章中,我们将继续介绍NLP应用程序中使用的一些主要深度学习模型。
【LLM】人工智能应用构建的十大预训练NLP语言模型

在人工智能领域,自然语言处理(NLP)被广泛认为是阅读、破译、理解和理解人类语言的最重要工具。有了NLP,机器可以令人印象深刻地模仿人类的智力和能力,从文本预测到情感分析再到语音识别。
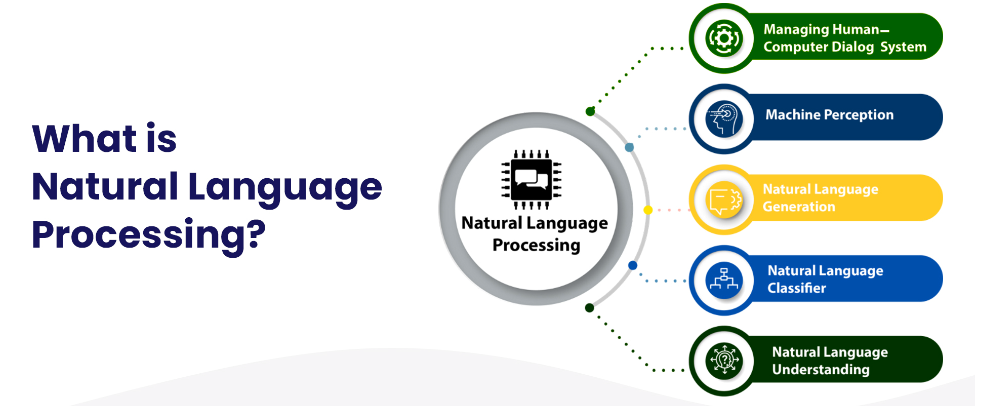
什么是自然语言处理?
【LLM】2023年大型语言模型培训
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易,但开发一个大型语言模型需要大量的计算机科学知识、时间和资源。我们撰写这篇文章是为了让商业领袖了解:
- 大型语言模型的定义
- 大型语言模型示例
- 大型语言模型的体系结构
- 大型语言模型的训练过程,
这样他们就可以有效地利用人工智能和机器学习。
什么是大型语言模型?
大型语言模型是一种机器学习模型,它在大型文本数据语料库上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译
大型语言模型通常基于深度学习神经网络,如Transformer架构,并在大量文本数据上进行训练,通常涉及数十亿个单词。较大的模型,如谷歌的BERT模型,使用来自各种数据源的大型数据集进行训练,这使它们能够为许多任务生成输出。
如果您是大型语言模型的新手,请查看我们的“大型语言模型:2023年完整指南”文章。
【LLM】大型语言模型:2023年完整指南
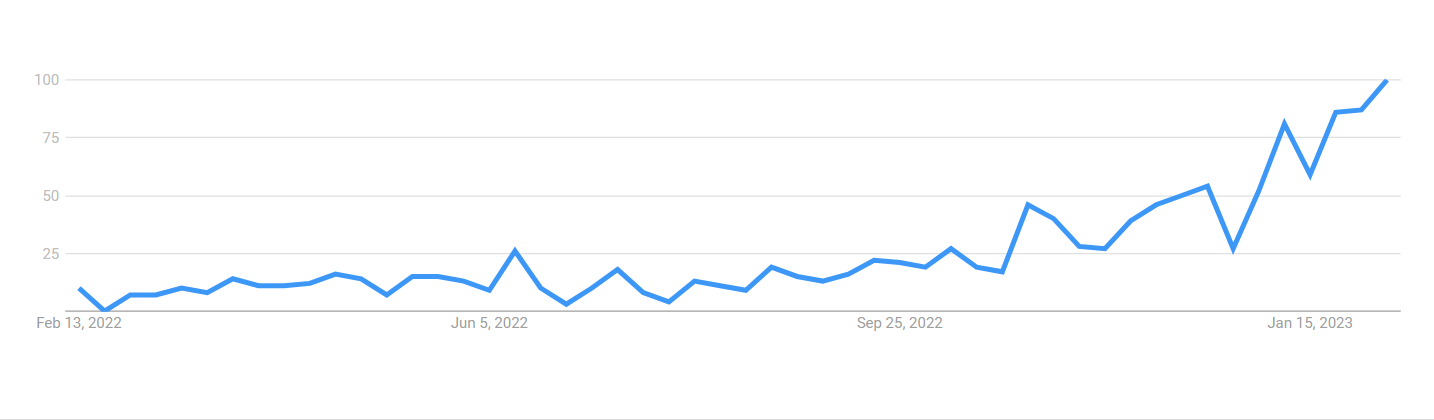
Figure 1: Search volumes for “large language models”
近几个月来,大型语言模型(LLM)引起了很大的轰动(见图1)。这种需求导致了利用语言模型的网站和解决方案的不断开发。ChatGPT在2023年1月创下了用户群增长最快的记录,证明了语言模型将继续存在。谷歌对ChatGPT的回应Bard于2023年2月推出,这也表明了这一点。
语言模型也为企业带来了新的可能性,因为它们可以: